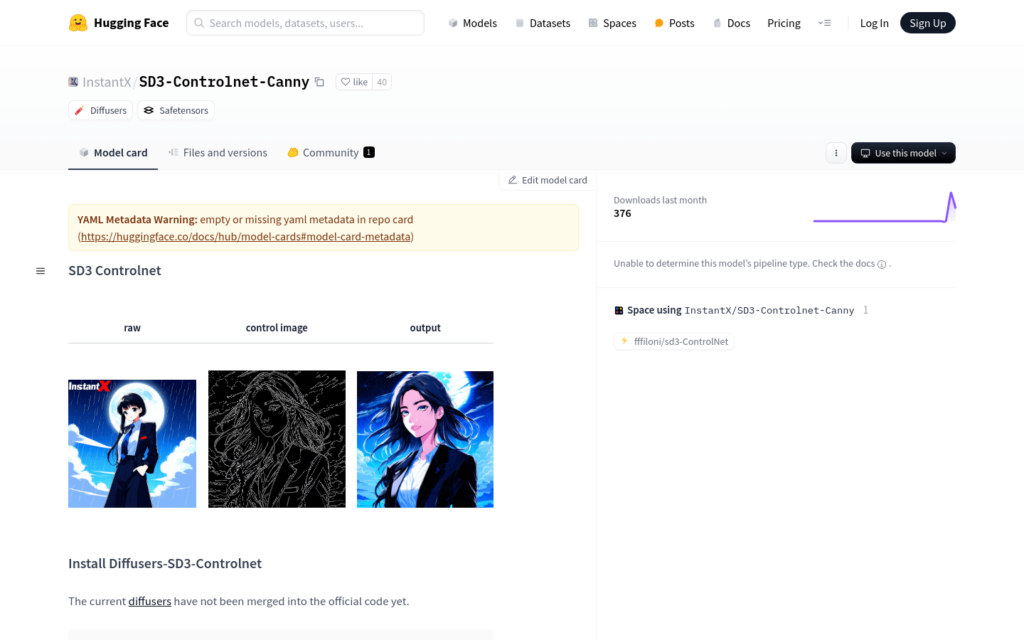
連結:https://huggingface.co/InstantX/SD3-Controlnet-Canny
SD3-Controlnet-Canny 是一種基於深度學習的影象生成模型,它能夠根據使用者提供的文本提示生成具有特定風格的影象。該模型利用控制網路技術,可以更精確地控制生成影象的細節和風格,從而提高影象生成的質量和多樣性。
需求人群:
- 目標受眾主要是影象生成領網網域的研究人員和開發者,以及對AI藝術創作感興趣的藝術家和設計師。該模型能夠幫助他們快速生成高質量的影象作品,提高創作效率。
使用場景示例:
- 生成動漫風格的人物插畫。
- 建立具有特定場景背景的影象,如帶有月亮和暴風雨背景的影象。
- 定製化生成具有特定元素的影象,例如在影象中新增文本。
產品特色:
- 根據文本提示生成特定風格的影象。
- 使用控制網路技術精確控制影象細節。
- 支援多種影象生成引數,如引導比例和影象尺寸。
- 能夠在GPU上執行,提高生成效率。
- 提供預訓練模型,方便使用者快速開始使用。
- 支援自訂控制影象,以影響生成結果。
使用教學:
1. 安裝必要的庫和依賴,如Diffusers-SD3-Controlnet。
2. 載入預訓練的模型和控制網路配置。
3. 定義文本提示和負面提示,以指導影象生成的方向。
4. 設定控制網路的具體引數,如控制權重和控制影象。
5. 執行影象生成過程,調整生成步數和引導比例。
6. 獲取生成的影象,並根據需要進行後續處理或展示。