Link:video-llava
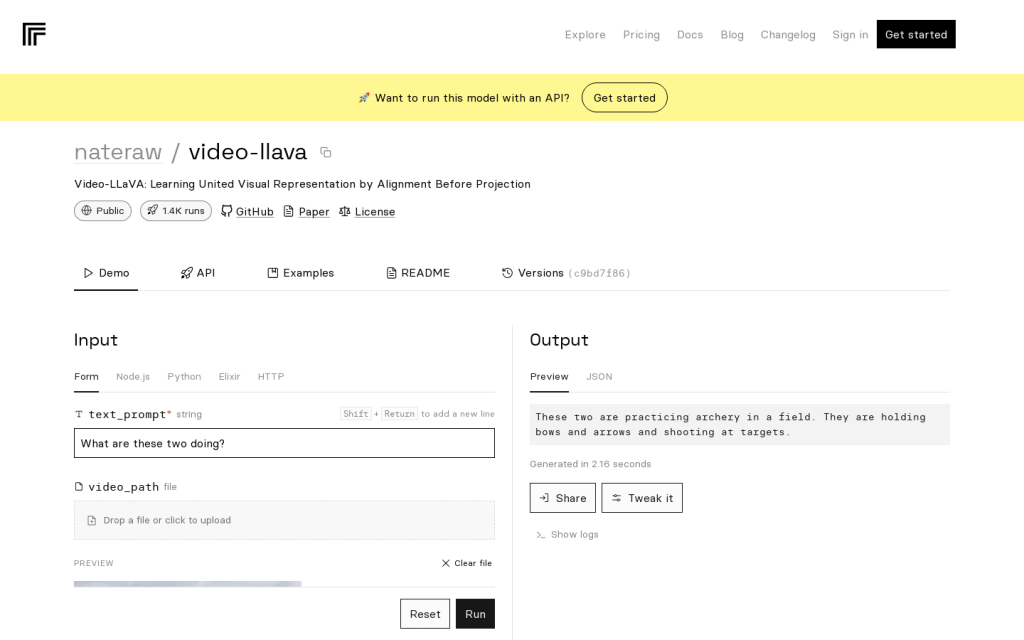
Video-LLaVA 是一個用於學習聯合視覺表示的模型,透過對齊前投影進行訓練。它可以將影片和影象表示進行對齊,從而實現更好的視覺理解。該模型具有高效的學習和推理速度,適用於影片處理和視覺任務。
需求人群:
"影片處理、視覺任務"
使用場景示例:
使用 Video-LLaVA 進行影片分類
利用 Video-LLaVA 進行影象檢索
應用 Video-LLaVA 進行目標跟蹤
產品特色:
學習聯合視覺表示
對齊前投影
高效的學習和推理速度
Link:video-llava
Video-LLaVA 是一個用於學習聯合視覺表示的模型,透過對齊前投影進行訓練。它可以將影片和影象表示進行對齊,從而實現更好的視覺理解。該模型具有高效的學習和推理速度,適用於影片處理和視覺任務。
需求人群:
"影片處理、視覺任務"
使用場景示例:
使用 Video-LLaVA 進行影片分類
利用 Video-LLaVA 進行影象檢索
應用 Video-LLaVA 進行目標跟蹤
產品特色:
學習聯合視覺表示
對齊前投影
高效的學習和推理速度