Link:gaia
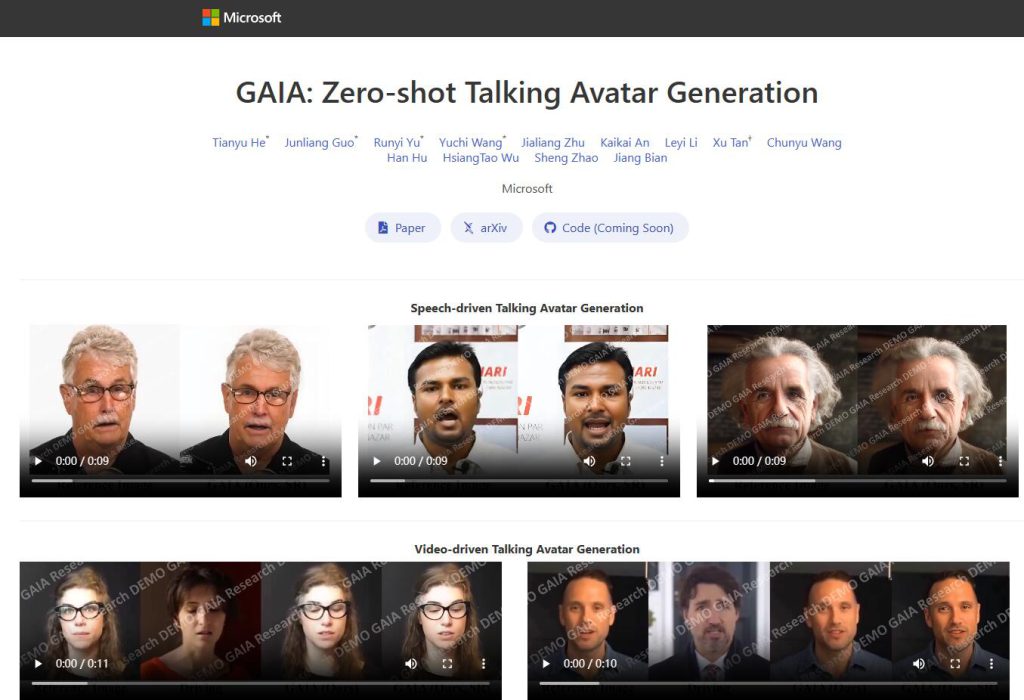
GAIA旨在從語音和單個肖像影象合成自然的對話影片。我們引入了GAIA(Avatar的生成AI),它消除了對話頭像生成中的領域先驗。GAIA分為兩個階段:1)將每幀分解為運動和外觀表示;2)在語音和參考肖像影象的條件下生成運動序列。我們收集了大規模高質量的對話頭像資料集,並在不同規模上對模型進行了訓練。實驗結果驗證了GAIA的優越性、可擴充套件性和靈活性。方法包括變分自動編碼器(VAE)和擴散模型。擴散模型被最佳化為在語音序列和影片片段中的隨機幀的條件下生成運動序列。GAIA可用於不同的應用,如可控對話頭像生成和文字指導的頭像生成。
需求人群:
"可用於生成自然的對話影片頭像,可用於研究和開發AI/ML技術。"
使用場景示例:
語音驅動的對話頭像生成
影片驅動的對話頭像生成
文字指導的頭像生成
產品特色:
語音驅動的對話頭像生成
影片驅動的對話頭像生成
姿態可控的對話頭像生成
完全可控的對話頭像生成
文字指導的頭像生成