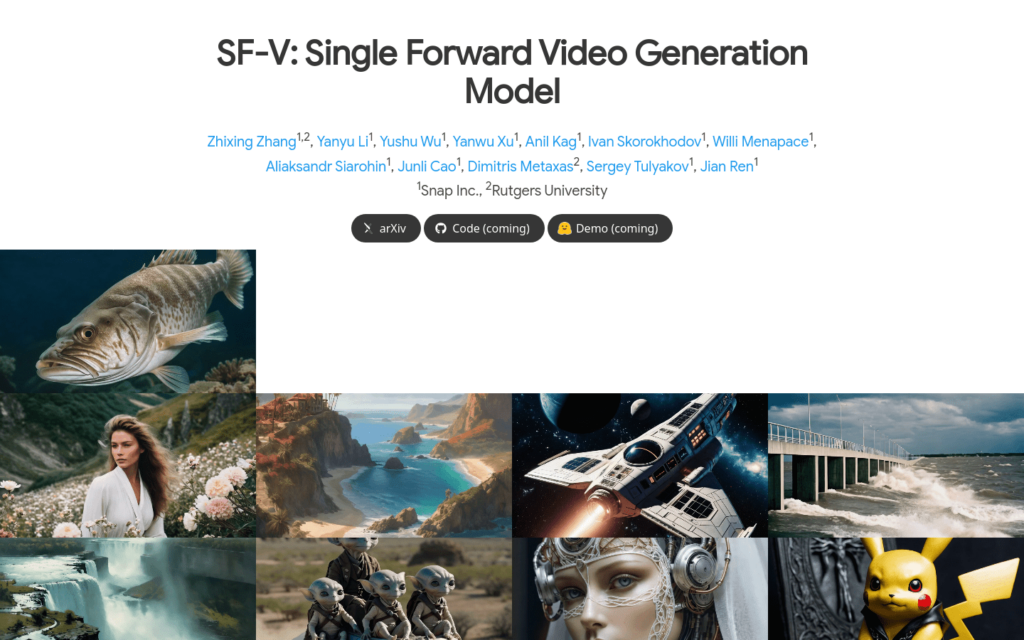
連結:https://snap-research.github.io/SF-V/
SF-V是一種基於擴散的影片生成模型,透過對抗訓練最佳化預訓練模型,實作了單步生成高質量影片的能力。這種模型在保持影片資料的時間和空間依賴性的同時,顯著降低了去噪過程的計算成本,為實時影片合成和編輯鋪平了道路。
需求人群:
- SF-V模型的目標受眾主要是需要進行高效影片合成和編輯的專業人士和研究人員。它適用於影片製作、虛擬實境內容建立、遊戲動畫製作等領網網域,因其高效率和高質量輸出,特別適合需要快速生成影片內容的場景。
使用場景示例:
- 用於生成虛擬實境環境中的動態背景影片。
- 在遊戲開發中快速生成動畫角色的動畫序列。
- 為電影后期製作提供高質量的影片素材合成。
產品特色:
- 利用對抗訓練對預訓練的影片擴散模型進行微調。
- 透過單步前向傳播合成高質量影片,捕捉影片資料的時間和空間依賴性。
- 與現有技術相比,實作了大約23倍的速度提升和更好的生成質量。
- 初始化生成器和鑑別器使用預訓練的影象到影片擴散模型的權重。
- 在訓練過程中,凍結UNet的編碼器部分,並僅更新空間和時間鑑別器頭部的引數。
- 提供影片比較結果和消融分析,展示方法的有效性。
使用教學:
1. 下載並安裝所需的軟體環境和依賴庫。
2. 訪問SF-V模型的網頁,瞭解其基本原理和功能。
3. 根據提供的程式碼(coming)和演示(coming),設定實驗環境。
4. 利用SF-V模型的初始化引數,配置生成器和鑑別器。
5. 透過對抗訓練對模型進行微調,最佳化影片生成質量。
6. 使用模型進行影片合成,觀察並評估生成的影片質量。
7. 根據需要調整模型引數,以適應不同的影片合成任務。