連結:https://github.com/lks-ai/ComfyUI-StableAudioSampler
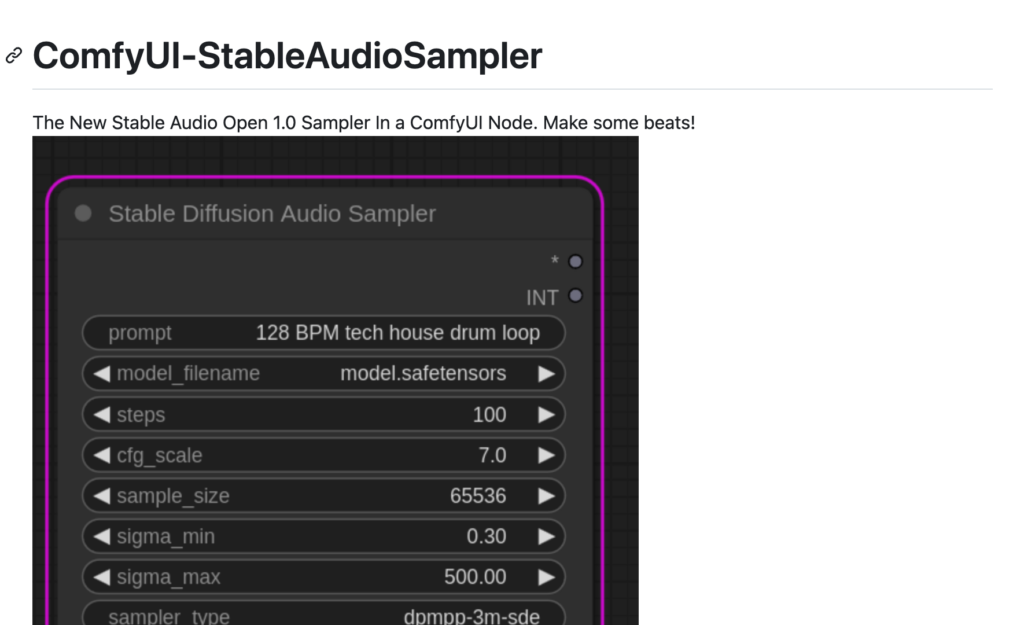
ComfyUI-StableAudioSampler 是一款整合在 ComfyUI 節點中的音訊取樣器外掛,它允許使用者生成音訊並輸出原始位元組和取樣率,支援所有原始 Stable Audio Open 引數,並可以儲存音訊到檔案。這個外掛是開源的,並且正在積極開發中,旨在為音樂製作者提供一個易於使用且功能強大的工具。
需求人群:
- 音樂製作人和音訊工程師可以利用 ComfyUI-StableAudioSampler 來創造獨特的音樂節奏和聲音效果,它提供了一個直觀的介面和強大的功能,使得音樂創作過程更加流暢和富有創意。
使用場景示例:
- 音樂製作人使用該外掛生成獨特的節奏和旋律
- 音訊工程師利用它來製作電影或遊戲的背景音樂
- 教育工作者在音樂製作課程中使用該工具教授學生
產品特色:
- 使用 HuggingFace 模型載入音訊
- 生成音訊並輸出原始位元組和取樣率
- 包含所有原始 Stable Audio Open 引數
- 支援將音訊儲存到檔案
- 計劃新增更多采樣器節點選項,如增益控制和剪輯
- 支援音訊格式與其他音訊節點包相容
- 正在進行程式碼重構以提高穩定性和效能
使用教學:
1. 確保已經設定好 HF_TOKEN 環境變數,因為模型載入目前還不能直接從儲存的檔案中進行。
2. 從 HuggingFace 下載所需的 Stable Audio Open 模型。
3. 將下載的模型放置在適當的目錄中,以便外掛能夠載入。
4. 打開 ComfyUI 並載入 ComfyUI-StableAudioSampler 外掛。
5. 根據需要配置外掛引數,如音訊輸出格式、取樣率等。
6. 使用外掛生成音訊,並將其儲存到指定的檔案中。
7. 如果遇到問題,可以檢視外掛文檔或在 GitHub 上提交問題報告。