連結:https://unianimate.github.io
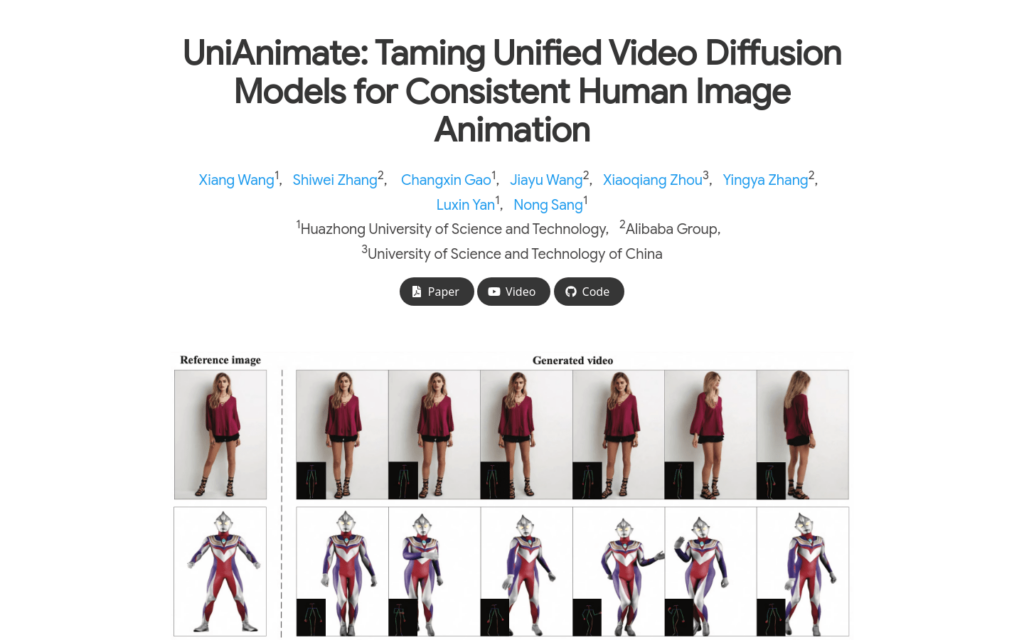
UniAnimate是一個用於人物影象動畫的統一影片擴散模型框架。它透過將參考影象、姿勢指導和噪音影片對映到一個共同的特徵空間,以減少最佳化難度並確保時間上的連貫性。UniAnimate能夠處理長序列,支援隨機噪音輸入和首幀條件輸入,顯著提高了生成長期影片的能力。此外,它還探索了基於狀態空間模型的替代時間建模架構,以替代原始的計算密集型時間Transformer。UniAnimate在定量和定性評估中都取得了優於現有最先進技術的合成結果,並且能夠透過迭代使用首幀條件策略生成高度一致的一分鐘影片。
需求人群:
- UniAnimate的目標受眾主要是電腦視覺和圖形學領網網域的研究人員和開發者,特別是那些專注於人物動畫和影片生成的專業人士。它適合需要生成高質量、長時序人物影片動畫的應用場景,如電影製作、遊戲開發、虛擬實境體驗等。
使用場景示例:
- 使用UniAnimate為電影製作生成高質量的人物動畫。
- 在遊戲開發中,利用UniAnimate生成連貫的人物動作序列。
- 虛擬實境體驗中,透過UniAnimate建立逼真的人物動態效果。
產品特色:
- 使用CLIP編碼器和VAE編碼器提取給定參考影象的潛在特徵。
- 將參考姿勢的表示納入最終參考指導,以便於學習參考影象中的人體結構。
- 使用姿勢編碼器對目標驅動的姿勢序列進行編碼,並與噪音輸入沿通道維度進行連線。
- 將連線的噪音輸入與參考指導沿時間維度堆疊,並輸入到統一影片擴散模型中以去除噪音。
- 在統一影片擴散模型中,時間模組可以是時間Transformer或時間Mamba。
- 採用VAE解碼器將生成的潛在影片對映到畫素空間。
使用教學:
首先,準備一張參考影象和一系列目標姿勢序列。
使用CLIP編碼器和VAE編碼器提取參考影象的潛在特徵。
將參考姿勢的表示與潛在特徵結合,形成參考指導。
透過姿勢編碼器對目標姿勢序列進行編碼,並與噪音影片結合。
將結合後的輸入資料輸入到統一影片擴散模型中進行噪音去除。
根據需要選擇時間模組,可以是時間Transformer或時間Mamba。
最後,使用VAE解碼器將處理後的潛在影片轉換為畫素級的影片輸出。