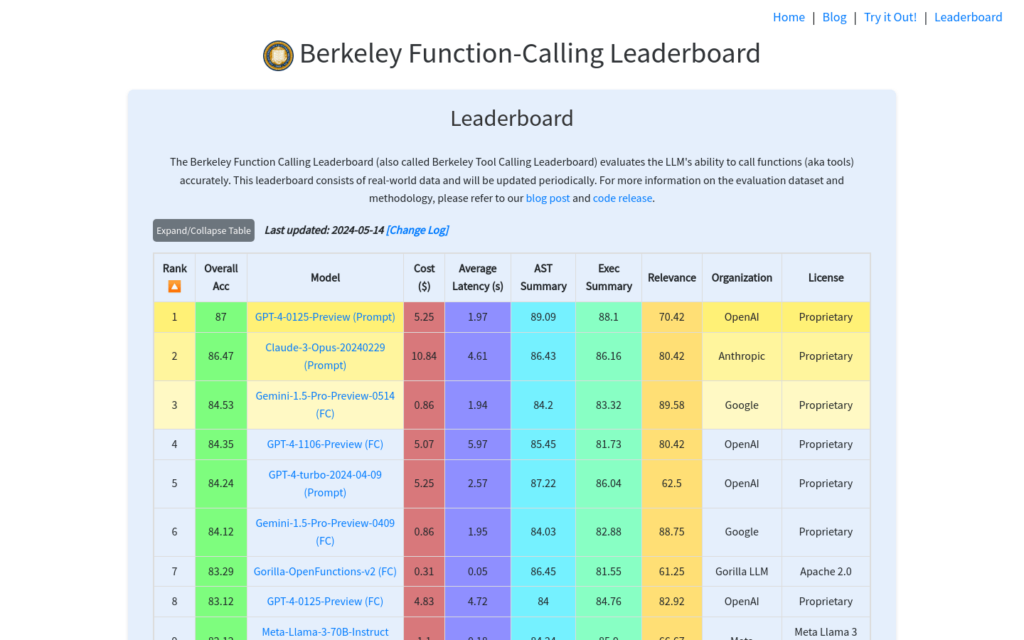
連結:https://gorilla.cs.berkeley.edu/leaderboard.html
門用來評估大型語言模型(LLMs)準確呼叫函式(或工具)能力的線上平臺。該排行榜基於真實世界資料,定期更新,提供了一個衡量和比較不同模型在特定程式設計任務上表現的基準。它對於開發者、研究人員以及對AI程式設計能力有興趣的使用者來說是一個寶貴的資源。
需求人群:
- 該產品適合AI研究人員、開發者以及對大型語言模型程式設計能力有興趣的技術人員。它可以幫助他們瞭解不同模型在函式呼叫任務上的表現,選擇最適合自己專案需求的模型,並評估模型的經濟性和效率。
使用場景示例:
- 研究人員使用該排行榜來比較不同LLMs在特定程式設計任務上的表現。
- 開發者利用排行榜資料選擇適合其應用場景的AI模型。
- 教育機構可能使用該平臺作為教學資源,展示AI技術的最新進展。
產品特色:
- 提供大型語言模型函式呼叫能力的評估
- 包含真實世界資料的評估集
- 排行榜定期更新,反映最新技術進展
- 提供詳細的錯誤型別分析,幫助使用者理解模型的優缺點
- 支援模型間比較,便於使用者選擇最合適的模型
- 提供模型成本和延遲的估算,幫助使用者做出經濟高效的選擇
使用教學:
訪問Berkeley Function-Calling Leaderboard網站。
檢視當前排行榜,瞭解各模型的得分和排名。
點選感興趣的模型,獲取該模型的詳細資訊和評估資料。
使用錯誤型別分析工具,瞭解模型在不同錯誤型別上的表現。
參考成本和延遲估算,評估模型的經濟性和響應速度。
如果需要,可以透過網站提供的聯絡方式,提交自己的模型或貢獻測試案例。