Link:dreamllm
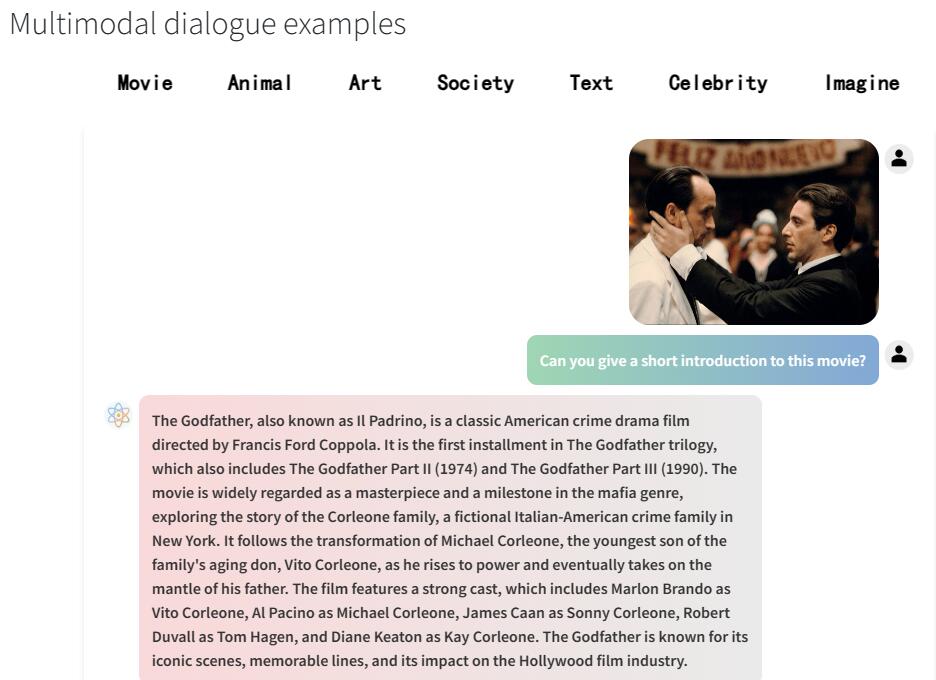
DreamLLM是一個學習框架,首次實現了多模態大型語言模型(LLM)在多模態理解和創作之間的協同效應。它透過直接在原始多模態空間中進行取樣,生成語言和影象的後驗模型。這種方法避免了像CLIP這樣的外部特徵提取器所固有的限制和資訊損失,從而獲得了更全面的多模態理解。DreamLLM還透過建模文字和影象內容以及無結構佈局的原始交叉文件,有效地學習了所有條件、邊緣和聯合多模態分佈。因此,DreamLLM是第一個能夠生成自由形式交叉內容的MLLM。全面的實驗證明瞭DreamLLM作為零樣本多模態通才的卓越效能,充分利用了增強的學習協同效應。
需求人群:
"多模態對話、電影、動物、藝術、社會、文字、名人想象"
產品特色:
生成多模態交叉內容
學習多模態分佈
生成圖片