連結:https://wangyuchi369.github.io/InstructAvatar/
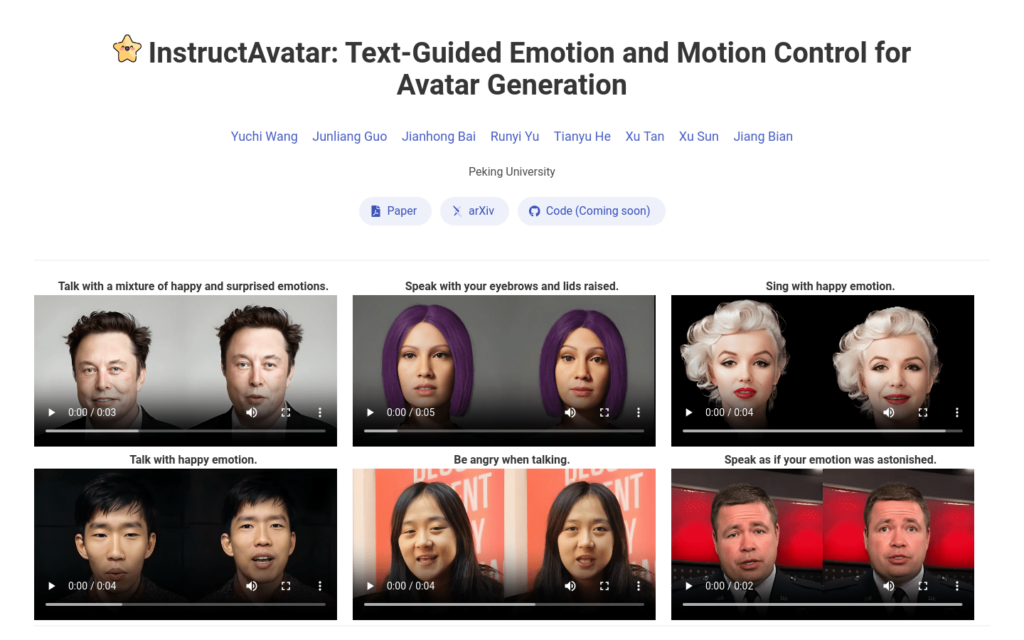
InstructAvatar是一個創新的文本引導方法,用於生成具有豐富情感表達的2D頭像。該模型透過自然語言接口控制頭像的情感和麵部動作,提供了細粒度控制、改進的互動性和對生成影片的泛化能力。它設計了一個自動化註釋流程來構建指令-影片配對的訓練資料集,並配備了一個新穎的雙分支擴散基礎生成器,可以同時根據音訊和文本指令預測頭像。實驗結果表明,InstructAvatar在細粒度情感控制、唇同步質量和自然度方面均優於現有方法。
需求人群:
InstructAvatar的目標受眾為AI研究者、頭像生成應用開發者以及對虛擬形象製作感興趣的使用者。它適合他們因為:1) 提供了一種新的頭像生成方法,可以用於研究和開發;2) 透過文本引導的方式簡化了頭像的情感和動作控制;3) 支援細粒度控制,使得生成的頭像更加生動和個性化;4) 具有改進的互動性和泛化能力,可以適應不同的應用場景。
使用場景示例:
- AI研究者使用InstructAvatar生成具有特定情感表達的頭像,用於情感辨識演演算法的訓練。
- 應用開發者利用InstructAvatar建立虛擬客服或遊戲角色,提供更自然的互動體驗。
- 內容創作者使用InstructAvatar生成個性化的虛擬形象,用於社交媒體或影片製作。
產品特色:
- 細粒度情感控制:根據文本指令精確控制頭像的情感表達。
- 面部動作生成:基於音訊和文本指令生成頭像的面部動作。
- 自動化註釋:構建指令-影片配對的訓練資料集。
- 雙分支擴散基礎生成器:同時處理音訊和文本,預測頭像。
- 改進的互動性:透過自然語言介面與使用者互動。
- 泛化能力:對生成影片具有較好的泛化能力。
使用教學:
步驟1:訪問InstructAvatar的官方網站。
步驟2:瞭解產品介紹和功能特點。
步驟3:根據需要選擇相應的文本指令來控制頭像的情感和動作。
步驟4:上傳使用者自己的頭像圖片,作為生成影片的基礎。
步驟5:透過自然語言接口輸入指令,如情感型別或面部動作。
步驟6:模型根據指令生成頭像影片。
步驟7:檢查生成的影片,確保滿足預期效果。
步驟8:根據需要調整指令或上傳新的頭像圖片,以最佳化生成效果。