Rerank 3:企業級搜尋與檢索增強型基礎模型
Rerank 3是一個針對企業搜尋和檢索輔助生成(RAG)系統最佳化的新型基礎模型。它支援多語種、多結構資料搜尋,提供高精度的語義重排,大幅提升響應準確度和延遲,同時大幅降低總體擁有成本。Rerank 3可無縫整合到任何資料庫或搜尋引擎中,並支援與現有應用程式原生搜尋功能無縫對接。

Rerank 3是一個針對企業搜尋和檢索輔助生成(RAG)系統最佳化的新型基礎模型。它支援多語種、多結構資料搜尋,提供高精度的語義重排,大幅提升響應準確度和延遲,同時大幅降低總體擁有成本。Rerank 3可無縫整合到任何資料庫或搜尋引擎中,並支援與現有應用程式原生搜尋功能無縫對接。
jina-ai/reader是一款網站轉換工具,可將任何URL轉換為LLM友好格式,以提高你的語言模型的輸出質量。只需簡單地將URL新增字首https://r.jina.ai/即可使用。支援標準模式和流式模式,提供更流暢的內容傳輸體驗。該工具由Jina AI開發,免費提供使用。

這是一個基於SDXL的ControlNet Tile模型,使用Hugging Face Diffusers訓練集,適用於Stable Diffusion SDXL ControlNet。它最初是為我自己的逼真模型訓練,用於終極放大過程以提高影象細節。使用合適的工作流程,它可以為高細節、高解析度的影象修復提供良好的結果。
Kimi Copilot是一款網頁總結助手,基於Kimi的長文本大模型,能夠一鍵總結網頁內容。安裝後,在瀏覽網路文章時點選外掛圖示,或使用快速鍵 Ctrl/Cmd+Shift+K,即可一鍵召喚Kimi.ai總結網頁內容。特點包括總結更全面、極簡易用、支援暗黑模式等。適用於個人使用者或需要快速總結網頁內容的使用者。
AmyMind 是一款免費的 AI 應用,可輕鬆建立和共享思維導圖、流程圖和 UML 圖。利用人工智慧技術,快速將想法轉化為全面的思維導圖,支援將文檔轉換為清晰有序的思維導圖,匯出至 PowerPoint、PDF 或 Word 格式。
musicgen-songstarter-v0.2是一個針對音樂製作人設計的音訊生成模型,專門用於生成有用的旋律循環。該模型在Splice樣本庫中的旋律循環資料集上進行了微調,能夠生成立體聲音訊,音訊頻率為32kHz。與v0.1版本相比,v0.2版本使用了三倍的獨特樣本,並且模型大小從中等提升到了大型。
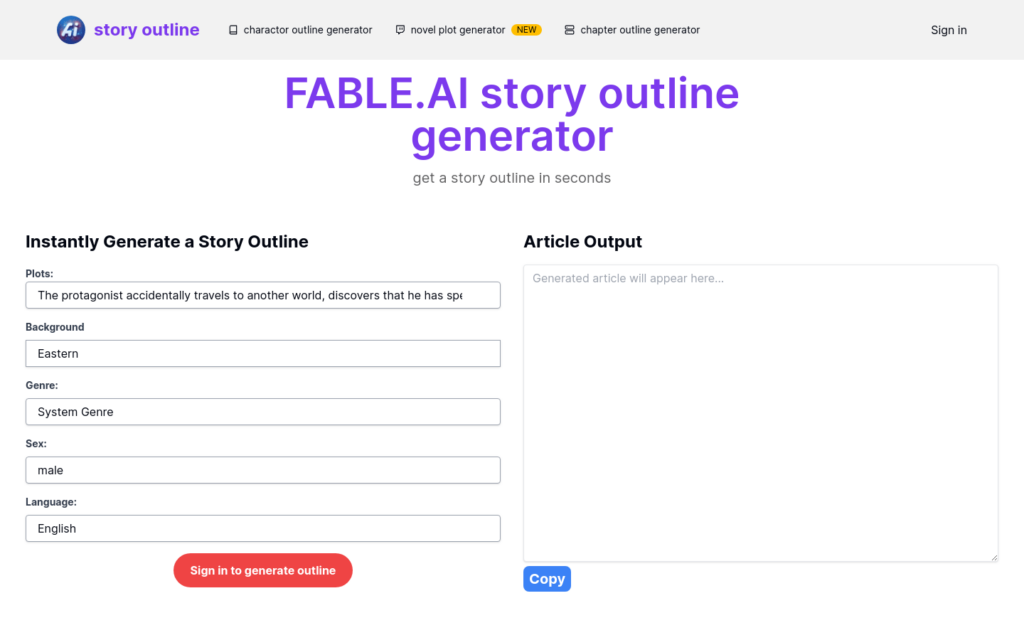
小說大綱生成器是一款基於人工智慧技術的創作工具,能夠快速生成詳細的情節結構,簡化小說規劃流程,幫助作者輕鬆構思故事。透過輸入關鍵資訊,如角色、背景、題材等,系統將自動生成小說大綱,為創作提供有力支援。定價靈活合理,定位於為寫作者提供創作靈感和方向。
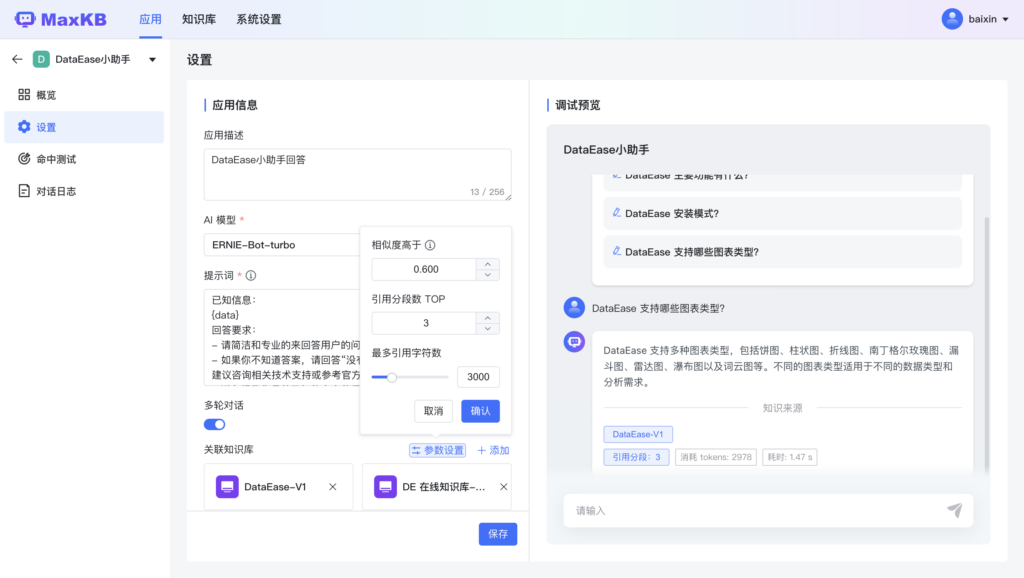
MaxKB 是一款基於 LLM 大語言模型的知識庫問答系統,旨在成為企業的最強大腦。支援文檔上傳、自動爬取線上文檔,智慧問答互動體驗好。支援快速嵌入到第三方業務系統。技術棧包括 Vue.js、Python/Django、Langchain、PostgreSQL/pgvector。
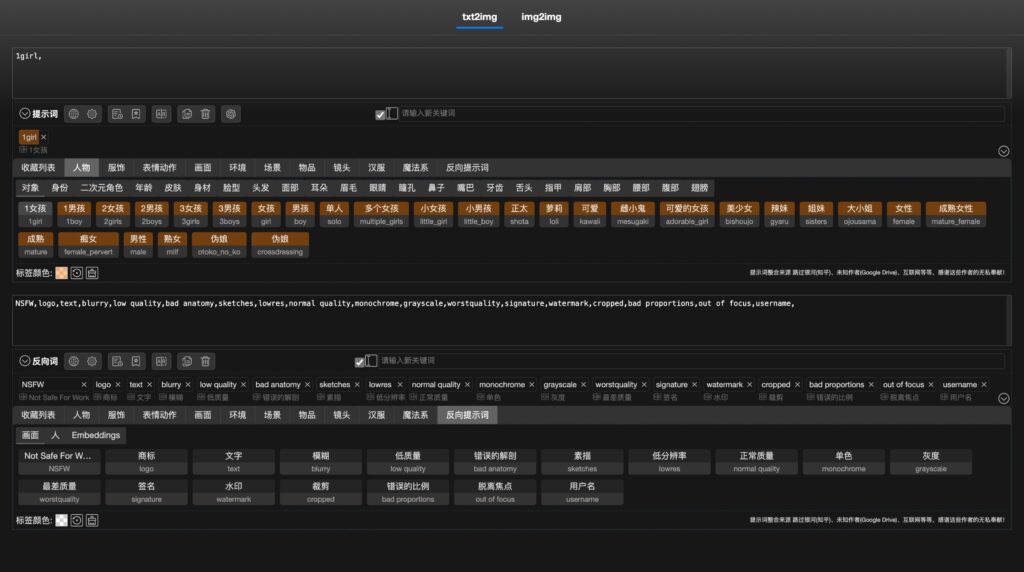
這個應用是一個獨立版本的提示詞管理工具,不需要依賴其他環境,可以在網頁中編寫和維護提示詞。使用者可以輕鬆地編寫和管理各種提示詞,提高工作效率。