Jobsolv:Jobsolv: AI驅動的自動工作搜尋、履歷製作和一鍵申請
Jobsolv是一個全能平臺,為你匹配高薪遠端職位、定製履歷,並一鍵申請。透過Jobsolv加速你的求職過程!
博查是一個無廣告干擾的答案引擎,您可以用自然語言提問,它會理解問題、細分檢索並生成準確的答案。博查的功能包括多模型AI搜尋、答案快如閃電、位元組雲雀大模型等。博查定位於提供快速、準確的答案解決方案。目前,博查為所有使用者提供免費使用。
Mirror AI 是一款個性化表情貼紙和頭像製作的行動電話應用。透過拍一張自拍照,使用Mirror AI的人工智慧面部辨識技術,可以建立一個與你非常相似的個性化卡通角色。該應用提供超過1000種不同情境和表情的表情貼紙,支援多種語言翻譯。


NOA Business Automation 是一款自動化即服務的工具,結合強大的人工智慧技術,為您提供最高的生產力。我們提供定製化工具和可擴充的資料基礎設施,幫助您實作高效的業務流程自動化。
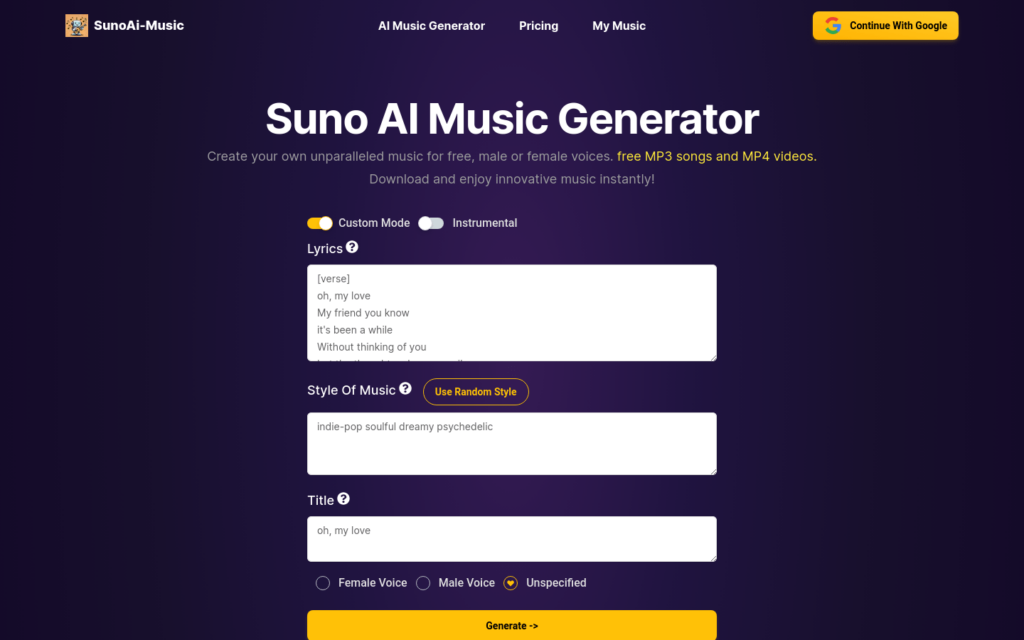
Suno AI音樂生成器是一款革命性的音樂創作工具,使用者可以免費使用該工具生成獨一無二的AI音樂,包括男聲、女聲、免費下載MP3和MP4音影片等。該工具具有簡單易用、高效快速的特點,支援自訂模式、隨機風格選擇等功能。

HuggingChat是一款iOS應用程式,旨在促進使用者與多家提供商(如Mistral AI、Meta和Google)的多個頂尖大型語言模型之間的無縫溝通。它可以滿足多種場景需求:激發創意,提供專家指導,促進教育與自我提升,提高工作效率,快速響應日常問題等。作為變革性AI技術的先鋒採用者,HuggingChat將讓您體驗與先進大語言模型對話的無限可能。

Meta Llama 3是Meta公司推出的新一代開源大型語言模型,效能卓越,在多項行業基準測試中表現出色。它可支援廣泛的使用場景,包括改善推理能力等新功能。該模型將在未來支援多語種、多模態,提供更長的上下文視窗和整體效能提升。Llama 3秉承開放理念,將被部署在主要雲服務、託管和硬體平臺上,供開發者和社群使用。
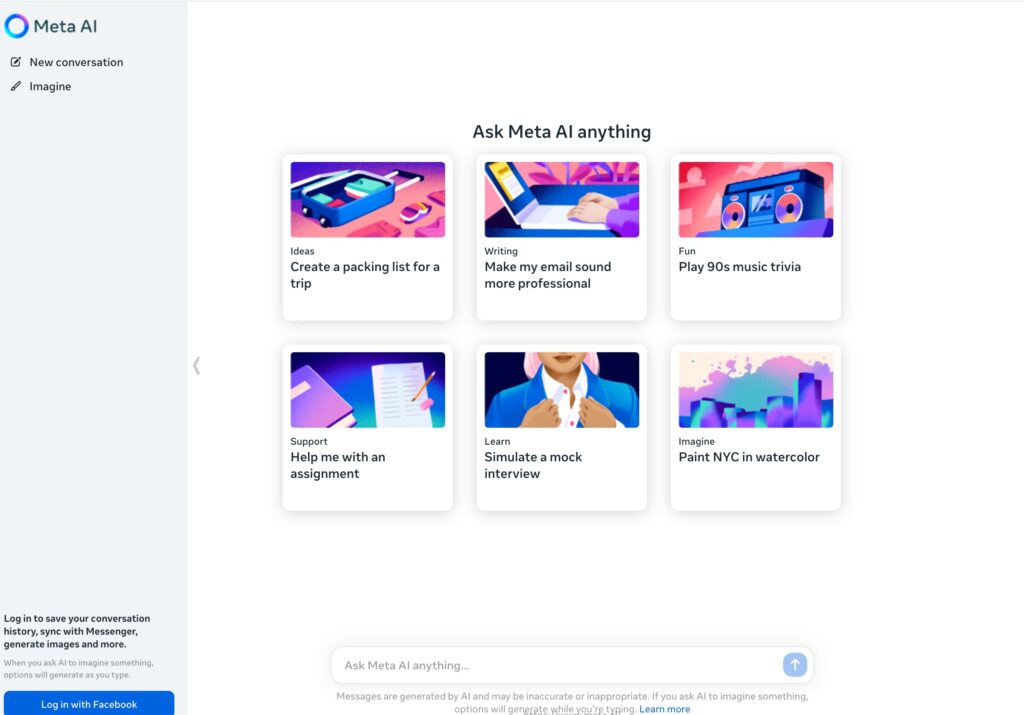
Meta AI 是一款功能強大的 AI 助理,建立在 Meta 的先進 AI 技術之上。它可以幫助您完成各種任務,如建立備忘單、潤色電子郵件寫作、回答問題等。同時它還具有影象生成功能,可以根據您的文字描述生成相應的影象。Meta AI 免費使用,致力於為使用者提供高效、智慧、多功能的 AI 體驗。