UNIMO-G:統一影象生成
UNIMO-G是一個簡單的多模態條件擴散框架,用於處理交錯的文字和視覺輸入。它包括兩個核心元件:用於編碼多模態提示的多模態大語言模型(MLLM)和用於基於編碼的多模態輸入生成影象的條件去噪擴散網路。
UNIMO-G是一個簡單的多模態條件擴散框架,用於處理交錯的文字和視覺輸入。它包括兩個核心元件:用於編碼多模態提示的多模態大語言模型(MLLM)和用於基於編碼的多模態輸入生成影象的條件去噪擴散網路。
ComfyUI-layerdiffusion是一個GitHub專案,提供了Layer Diffusion模型的自定義節點實現。該專案允許使用者透過Python依賴安裝,並且目前僅支援SDXL模型。專案的目標是為ComfyUI使用者提供Layer Diffusion模型的便捷整合。
Arteus AI Image Generator是一款由Arteus AI開發的尖端工具,利用先進的人工智慧技術從文字提示中建立影象。只需描述您想生成的內容,Arteus AI就能產生出來。該工具採用了生成對抗網路(GANs)或變分自編碼器(VAEs)等複雜的深度學習演演算法,透過學習資料集中的模式並根據輸入引數生成影象,從而確保高質量輸出。Arteus AI Image Generator非常靈活,可以建立各種型別的影象,包括逼真的照片、抽象藝術、風景、肖像等。使用者可以透過調整引數或提供具體指令來定製生成的影象。

WxArt Ai是一款專業的繪畫軟體,擁有強大的AI引擎,為使用者提供一系列創新功能。利用先進的AI內容生成技術,WxArt Ai可以建立各種圖片,包括基於文字的藝術和基於影象的藝術。無論您是尋找墨水風格、多彩動漫、逼真風格還是二維作品,WxArt Ai都可以滿足您的多樣需求。
偽靈活基礎模型(ptx0/pseudo-flex-base)是基於 Diffusion 技術的文字到影象生成模型。它透過將文字描述轉換為逼真的影象,提供了靈活的影象生成能力。該模型可以根據給定的文字提示生成與文字描述相符合的影象,具有高度的靈活性和生成效果。該模型還具有穩定的效能和可靠的訓練基礎,可以廣泛應用於人工智慧領域的影象生成任務。

Stable Diffusion – AI藝術(全球)使用AI藝術技術幫助您建立精美影象。支援MidJourney和SDXL 1.0模型,使您的創作簡單易用。我們的產品旨在為使用者提供豐富多彩的AI影象生成功能,包括影象素材、頭像、壁紙、封面圖片和動漫插圖。無論您需要什麼樣的圖片,從可愛的頭像到情侶頭像,甚至各種尺寸的圖片,我們都可以滿足您的需求。
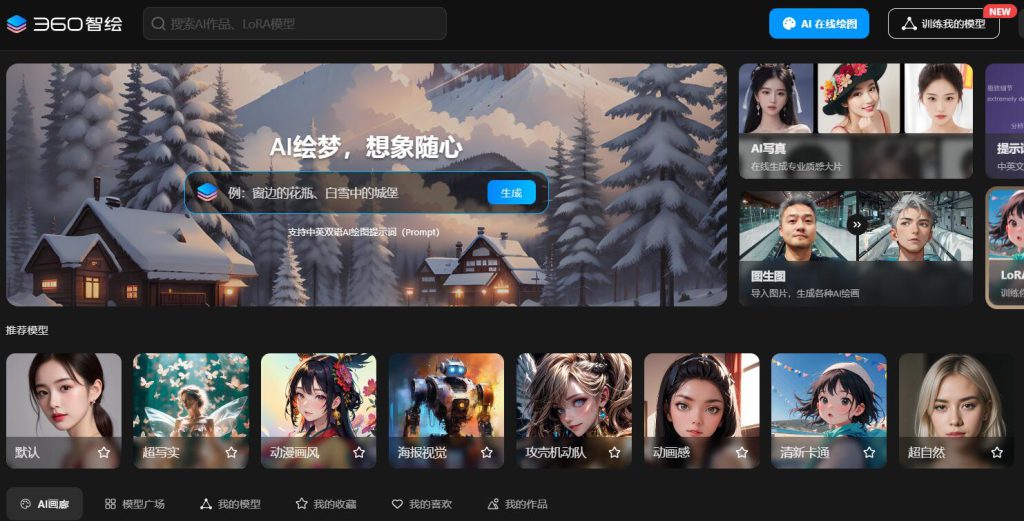
360 智繪是一款 AI 線上繪圖工具,提供 AI 繪圖、AI 寫真、提示詞生成器、圖生圖等多種功能。使用者可以透過輸入提示詞或匯入圖片,生成各種風格的繪畫作品。產品使用簡單方便,適用於個人創作、設計等多種場景。
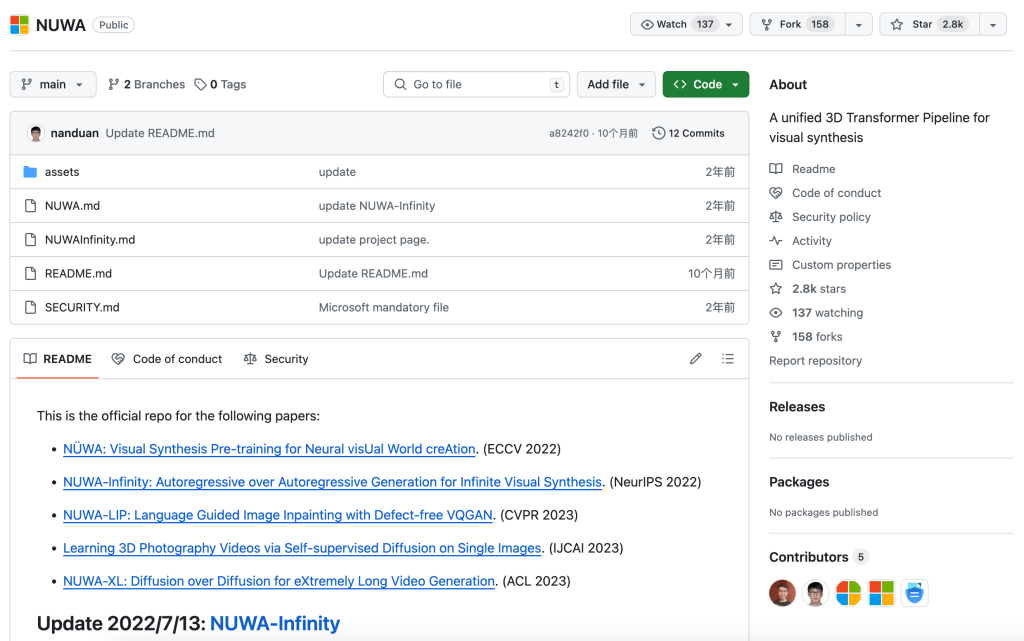
NUWA是由微軟開發的一系列研究專案,包括NUWA、NUWA-Infinity、NUWA-LIP、Learning 3D Photography Videos和NUWA-XL。這些專案涉及視覺合成的預訓練模型,能夠生成或操縱視覺資料,如影象和影片,以執行多種視覺合成任務。
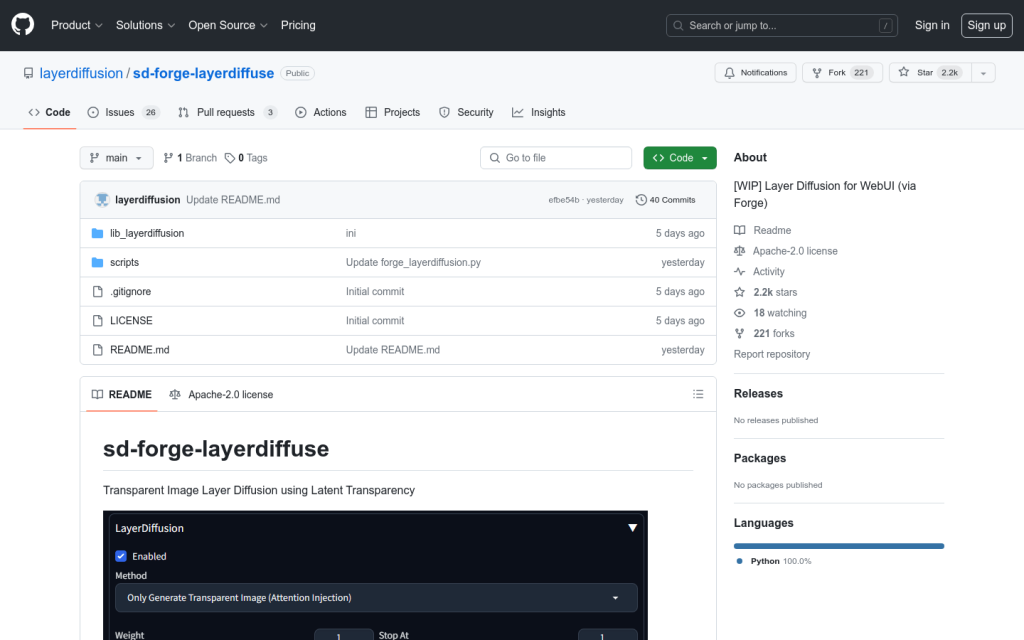
sd-forge-layerdiffuse是一個用於生成透明影象和圖層的工作在進行中的擴充套件,它利用了潛在透明度技術。該工具目前支援影象生成和基本圖層功能,但透明影象到影象的轉換尚未完成。程式碼庫高度動態,未來一個月可能會有大量變化。
Stable Diffusion 是一個深度學習模型,可從文字描述生成影象。透過輸入描述性文字,可以生成高質量的逼真影象。使用者可以免費線上使用 Stable Diffusion,生成各種型別的藝術影象。