HyperHuman:生成逼真的人類影象
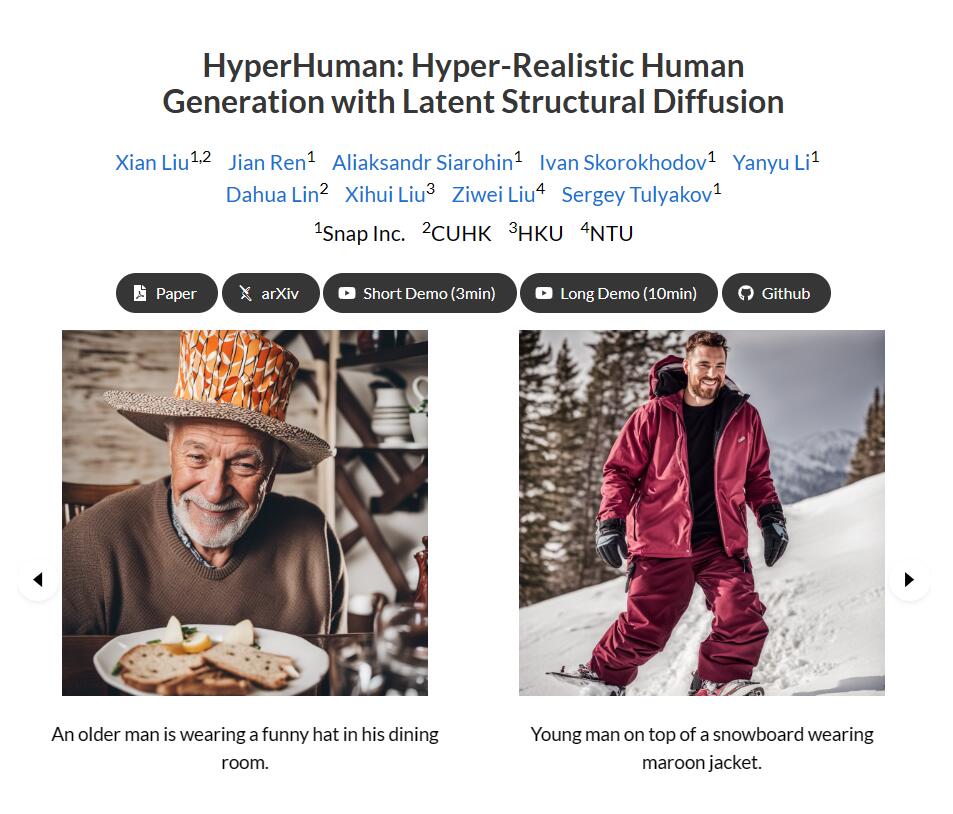
HyperHuman是一個生成逼真的人類影象的模型。該模型透過捕捉人類影象的結構性特徵,從粗略的身體骨架到細粒度的空間幾何形狀,生成具有連貫性和自然性的人類影象。HyperHuman包括三個部分:1)構建一個大規模的人類資料集HumanVerse,其中包含340M張影象和全面的註釋,如人體姿勢、深度和表面法線;2)提出一個潛在結構擴散模型,該模型同時去噪深度、表面法線和合成的RGB影象。我們的模型在一個統一的網路中強制學習影象外觀、空間關係和幾何形狀,模型中的每個分支都具有結構感知性和紋理豐富性;3)最後,為了進一步提高視覺質量,我們提出了一個結構引導的細化器,用於更詳細的高解析度生成。大量實驗證明,我們的模型在各種場景下生成了具有高真實感和多樣性的人類影象,達到了最先進的效能。