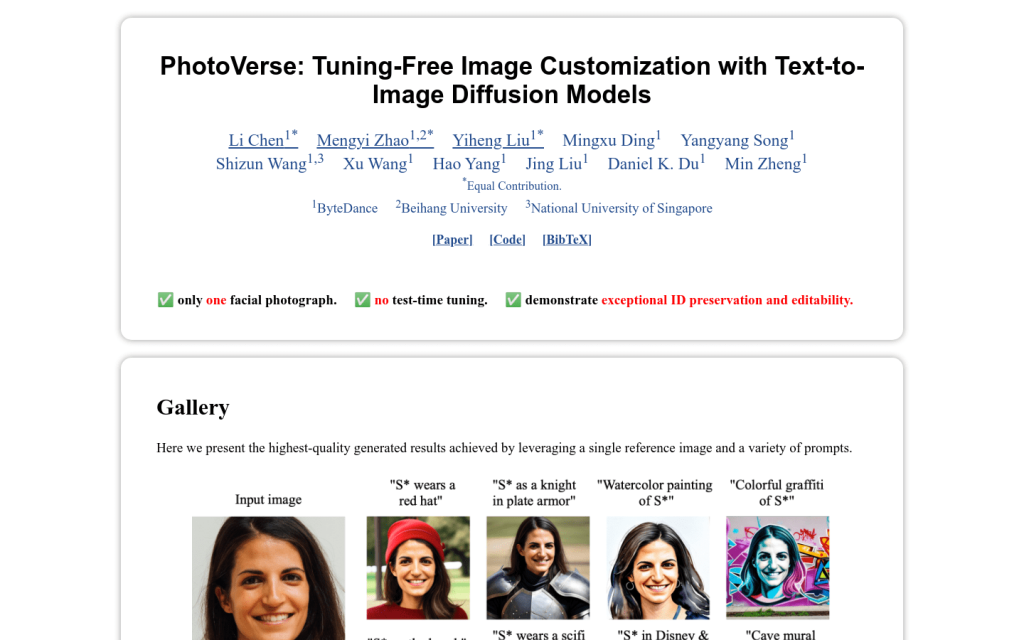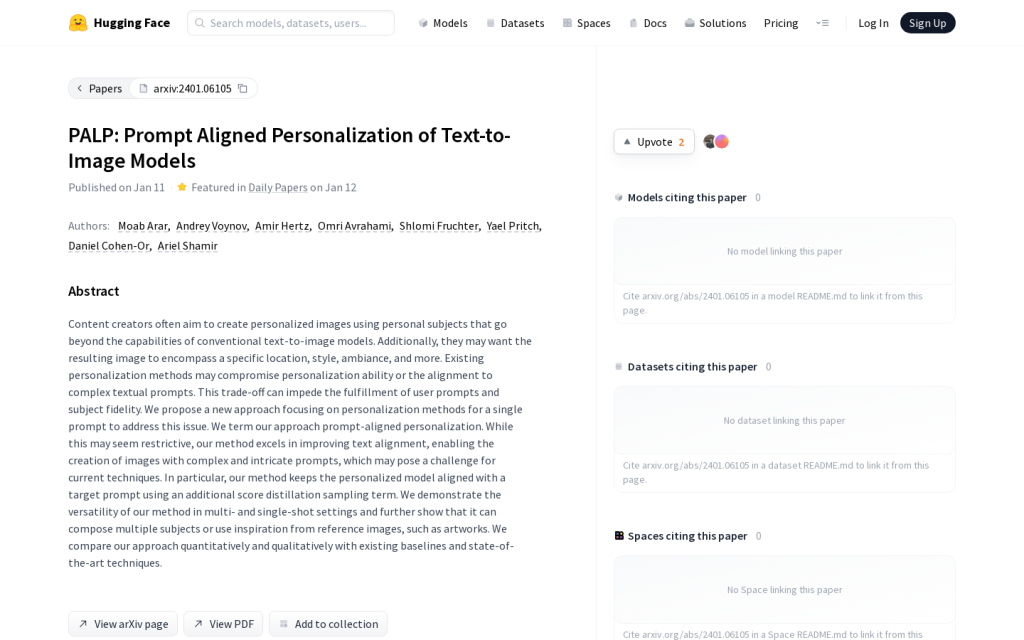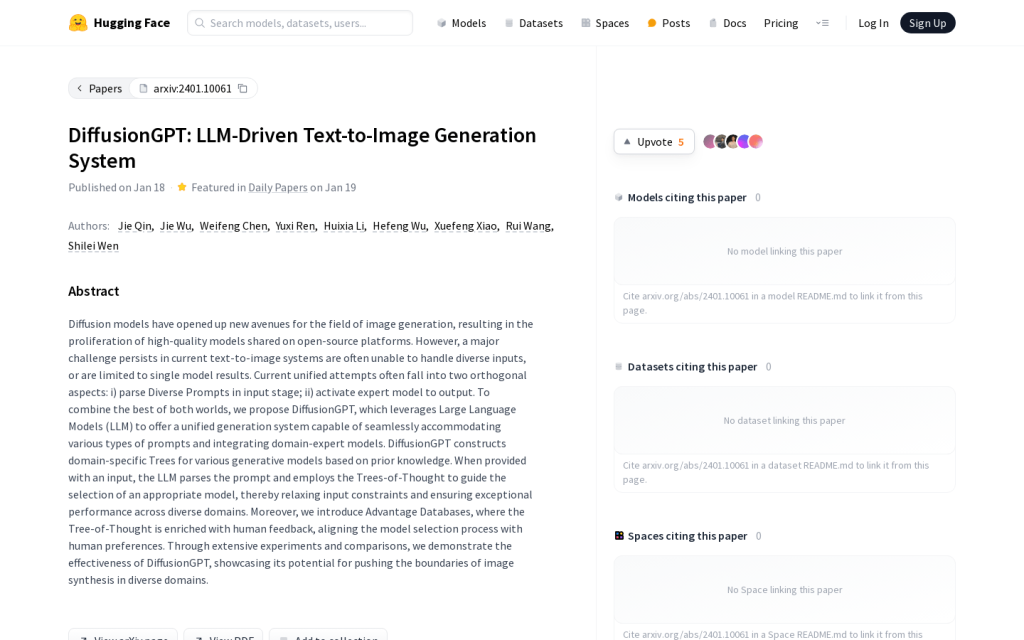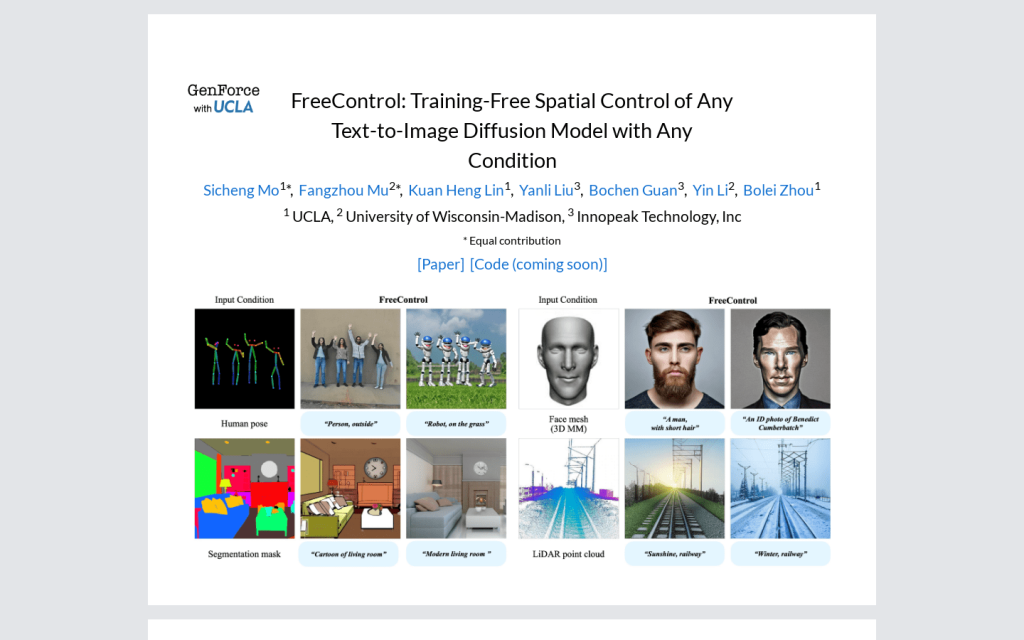
Canva Text to Image:透過 AI 文字生成影象,給你完美適合的創作靈感。
Canva 的 AI 影象生成器應用程式讓你隨時擁有完美的影象——即使它還不存在。使用"文字到影象"功能,您只需輸入文字,就能生成用於創意專案(如簡報或社交媒體帖子)的影象。選擇不同的影象風格,如水彩、電影、霓虹燈等。您還可以使用 Canva 的其他 AI 生成器應用程式,如 DALL·E 和 Imagen。無論您是內容創作者、企業家還是藝術家,都可以使用這些工具高效建立獨特的影象和品牌素材。Canva 提供免費和付費訂閱,付費版可以每月生成更多影象。