Link:lavi-bridge
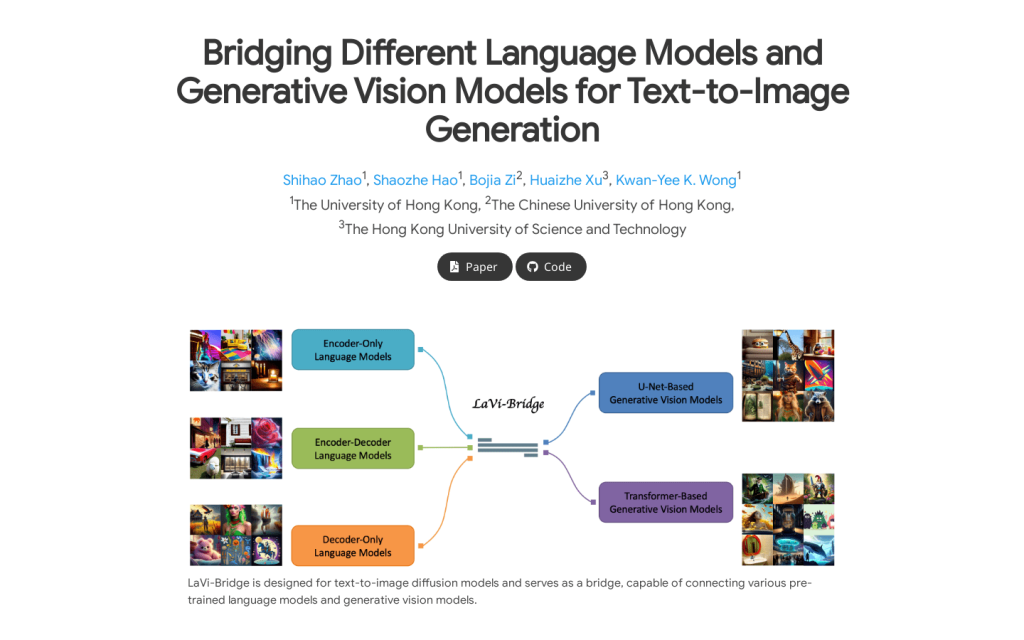
LaVi-Bridge是一種針對文字到影象擴散模型設計的橋接模型,能夠連線各種預訓練的語言模型和生成視覺模型。它透過利用LoRA和介面卡,提供了一種靈活的插拔式方法,無需修改原始語言和視覺模型的權重。該模型與各種語言模型和生成視覺模型相容,可容納不同的結構。在這一框架內,我們證明瞭透過整合更高階的模組(如更先進的語言模型或生成視覺模型)可以明顯提高文字對齊或影象質量等能力。該模型經過大量評估,證實了其有效性。
需求人群:
"LaVi-Bridge可用於文字到影象生成任務,特別是在需要整合更先進語言模型或視覺模型的場景。"
使用場景示例:
使用LaVi-Bridge將GPT-3語言模型與Stable Diffusion視覺模型整合,生成高質量影象
利用LaVi-Bridge將Llama語言模型與PixArt視覺模型連線,提高文字描述與生成影象的匹配度
透過LaVi-Bridge框架,快速評估不同語言模型和視覺模型在文字到影象生成任務上的效能
產品特色:
連線不同的語言模型和生成視覺模型
透過LoRA和介面卡實現靈活性和插拔式整合
提高文字描述與生成影象的對齊度
提升影象質量