連結:https://ictnlp.github.io/StreamSpeech-site/
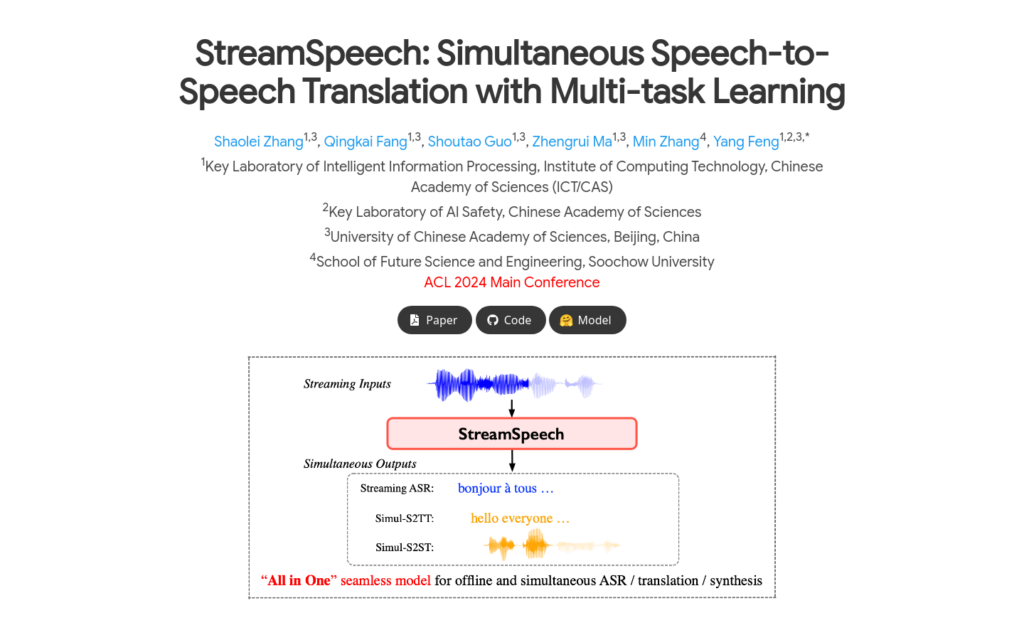
StreamSpeech是一款基於多工學習的實時語音到語音翻譯模型。它透過統一框架同時學習翻譯和同步策略,有效辨識流式語音輸入中的翻譯時機,實作高質量的實時通訊體驗。該模型在CVSS基準測試中取得了領先的效能,並能提供低延遲的中間結果,如ASR或翻譯結果。
需求人群:
StreamSpeech適用於需要實時跨語言交流的專業人士,如國際會議的同步口譯員、多語言商務溝通者以及語言學習者。它透過減少翻譯延遲,提高了交流效率,使得不同語言背景的人們能夠無障礙地進行實時對話。
使用場景示例:
- 國際會議中,使用StreamSpeech進行同步口譯。
- 跨國公司使用StreamSpeech進行遠端會議,實作實時多語言溝通。
- 語言學習者使用StreamSpeech練習不同語言的聽力和口語。
產品特色:
- 支援流式語音辨識(ASR)
- 支援非自迴歸語音到文本翻譯(NAR-S2TT)
- 支援語音到單元翻譯(S2UT)
- 能夠實時生成目標語音
- 在翻譯過程中提供高質量的中間結果
- 支援多種語言的翻譯,如法英、西班牙英、德英等
使用教學:
1. 訪問StreamSpeech網站並瞭解產品基本資訊。
2. 選擇源語言和目標語言,根據需要進行設定。
3. 上傳或實時輸入源語言的語音資料。
4. 系統將自動辨識語音並進行翻譯。
5. 翻譯後的語音將以目標語言的形式輸出。
6. 在翻譯過程中,可以實時檢視中間的ASR或翻譯結果。
7. 根據反饋調整翻譯引數,最佳化翻譯質量。