Florence-2-large:先進的視覺基礎模型,支援多種視覺和視覺-語言任務
Florence-2-large是由微軟開發的先進視覺基礎模型,採用基於提示的方法處理廣泛的視覺和視覺-語言任務。該模型能夠解釋簡單的文本提示來執行如影象描述、目標偵測和分割等任務。它利用包含54億註釋的5.4億影象的FLD-5B資料集,精通多工學習。其序列到序列的架構使其在零樣本和微調設定中均表現出色,證明是一個有競爭力的視覺基礎模型。
Florence-2-large是由微軟開發的先進視覺基礎模型,採用基於提示的方法處理廣泛的視覺和視覺-語言任務。該模型能夠解釋簡單的文本提示來執行如影象描述、目標偵測和分割等任務。它利用包含54億註釋的5.4億影象的FLD-5B資料集,精通多工學習。其序列到序列的架構使其在零樣本和微調設定中均表現出色,證明是一個有競爭力的視覺基礎模型。
Florence-2是由微軟開發的高階視覺基礎模型,採用基於提示的方法處理廣泛的視覺和視覺-語言任務。該模型能夠解釋簡單的文本提示,執行如描述、目標偵測和分割等任務。它利用包含54億個註釋的5.4億張影象的FLD-5B資料集,精通多工學習。模型的序列到序列架構使其在零樣本和微調設定中都表現出色,證明其為有競爭力的視覺基礎模型。
Florence-2是一個新型的視覺基礎模型,它透過統一的、基於提示的表示方式,能夠處理多種電腦視覺和視覺-語言任務。它設計為接受文本提示作為任務指令,並以文本形式生成期望的結果,無論是影象描述、目標偵測、定位還是分割。這種多工學習設定需要大規模、高質量的註釋資料。
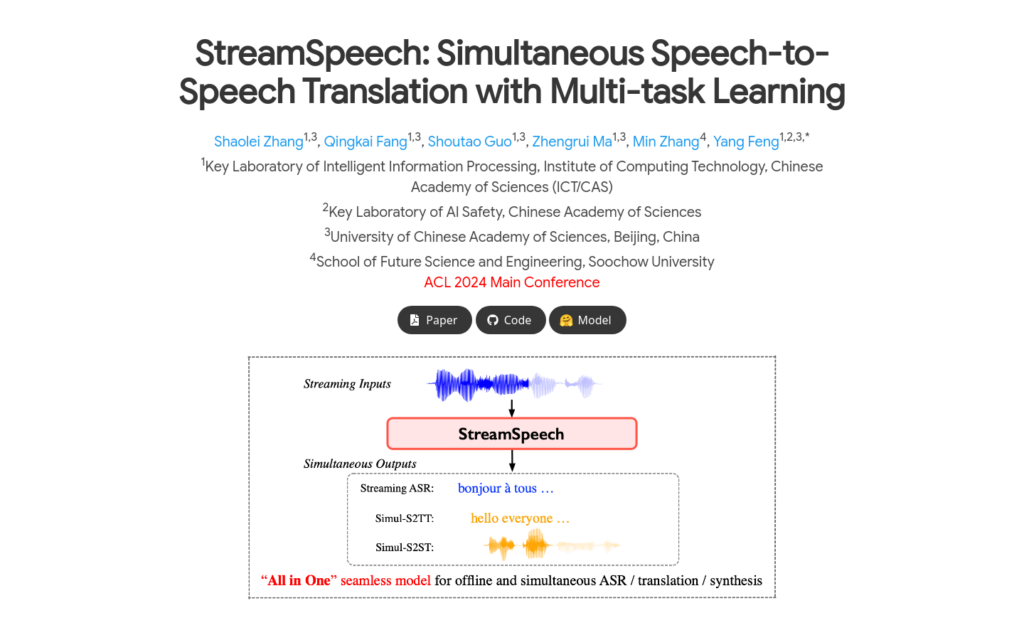
StreamSpeech是一款基於多工學習的實時語音到語音翻譯模型。它透過統一框架同時學習翻譯和同步策略,有效辨識流式語音輸入中的翻譯時機,實作高質量的實時通訊體驗。該模型在CVSS基準測試中取得了領先的效能。
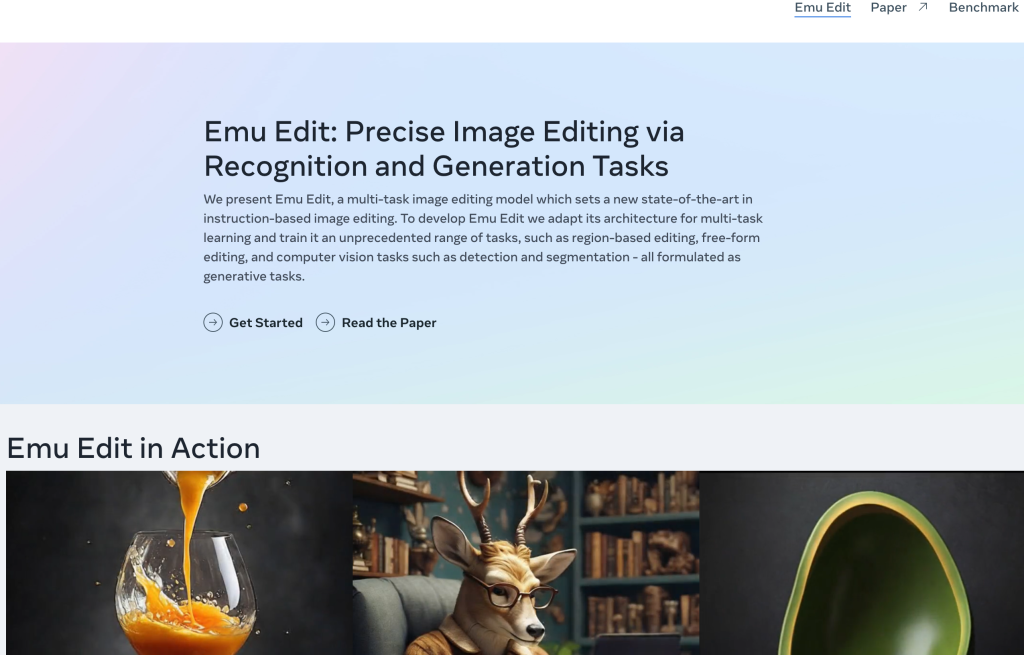
Emu Edit是一款多工影象編輯模型,透過識別和生成任務完成精準影象編輯,並在此領域內取得了最新的技術突破。Emu Edit的架構針對多工學習進行了最佳化,並在眾多工上進行訓練,包括基於區域的編輯、自由形式的編輯以及檢測和分割等計算機視覺任務。除此之外,為了更有效地處理這多種任務,我們引入了學習到的任務嵌入概念,用於指導生成過程以正確執行編輯指令。我們的模型經過多工訓練和使用學習到的任務嵌入都能顯著提升準確執行編輯指令的能力。
Emu Edit還支援對未見任務的快速適應,透過任務倒轉實現少樣本學習。在這個過程中,我們保持模型權重不變,僅更新任務嵌入來適應新任務。我們的實驗證明,Emu Edit能夠迅速適應新任務,如超解析度、輪廓檢測等。這使得在標註樣本有限或計算預算有限的情況下,使用Emu Edit進行任務倒轉特別有優勢。
為了支援對基於指令的影象編輯模型的嚴格且有根據的評估,我們還收集並公開發布了一個新的基準資料集,其中包含七種不同的影象編輯任務:背景修改(background)、綜合影象變化(global)、風格修改(style)、對象移除(remove)、對象新增(add)、區域性修改(local)以及顏色/紋理修改(texture)。此外,為了與Emu Edit進行正確比較,我們還分享了Emu Edit在資料集上的生成結果。
Emu Edit 2023 Meta保留所有版權