GoMate:基於RAG框架的可靠輸入和可信輸出系統
GoMate是一個基於Retrieval-Augmented Generation (RAG)框架的模型,專注於提供可靠輸入和可信輸出。它透過結合檢索和生成技術,提高資訊檢索和文本生成的準確性和可靠性。GoMate適用於需要高效、準確資訊處理的領網域,如自然語言處理、知識問答等。
GoMate是一個基於Retrieval-Augmented Generation (RAG)框架的模型,專注於提供可靠輸入和可信輸出。它透過結合檢索和生成技術,提高資訊檢索和文本生成的準確性和可靠性。GoMate適用於需要高效、準確資訊處理的領網域,如自然語言處理、知識問答等。
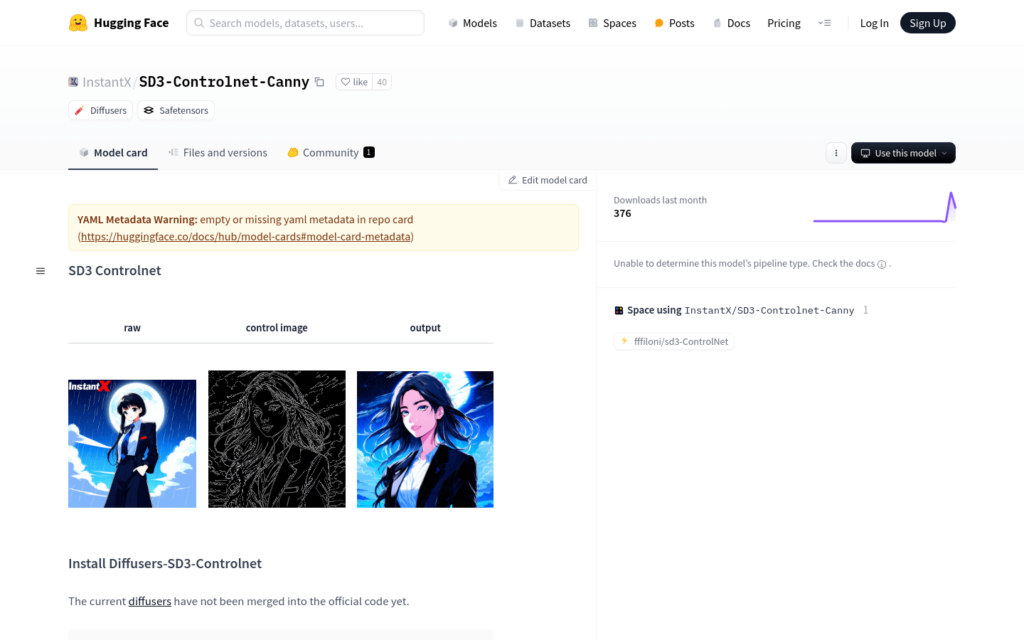
SD3-Controlnet-Canny 是一種基於深度學習的影象生成模型,它能夠根據使用者提供的文本提示生成具有特定風格的影象。該模型利用控制網路技術,可以更精確地控制生成影象的細節和風格,從而提高影象生成的質量和多樣性。
EMMA是一個基於最前沿的文本到影象擴散模型ELLA構建的新型影象生成模型,能夠接受多模態提示,透過創新的多模態特徵聯結器設計,有效整合文本和補充模態資訊。該模型透過凍結原始T2I擴散模型的所有引數,並僅調整一些額外層,揭示了預訓練的T2I擴散模型可以秘密接受多模態提示的有趣特性。
Dream Machine是由Luma Labs開發的一款先進的人工智慧模型,旨在快速從文本和圖片生成高質量的、逼真的影片。這個高度可擴充且高效的變換模型直接在影片上訓練,使其能夠產生物理上準確、一致且充滿事件的鏡頭。
CV Screener是MindPal公司提供的一款線上AI解決方案,旨在幫助現代專業人士提高工作效率。透過4步CV篩選范本,使用者可以輕鬆評估求職者,辨識頂尖人才。產品背景資訊包括MindPal公司致力於採用AI技術提升工作效率,並且產品支援結果儲存、自訂資料新增、工作流程定製等功能。
NewRA是一個基於雲端的AI聊天機器人平臺,支援現代廣泛使用的AI模型。它利用企業資料和資訊集,在幾分鐘內構建AI驅動的聊天機器人。NewRA提供個性化應用,使使用者能夠利用現有資料和文檔,增強AI驅動的決策制定和操作。

Masked Diffusion Language Models (MDLM) 是一種新型的語言模型,它透過遮蔽和擴散機制來生成高質量的文本資料。MDLM 透過改進的訓練方法和簡化的目標函式,提高了遮蔽擴散模型的效能,使其在語言建模基準測試中達到了新的最佳狀態,並接近自迴歸模型的困惑度。
Humanize AI Text是一個先進的AI文本人性化工具,能夠將AI生成的文本轉換成更自然、更具人性化的文本,以避免AI偵測,並提升內容的吸引力和可讀性。它支援多語言,增強了內容的全球可訪問性。主要優點包括內容塑形、多語言掌握、可讀性提升、寫作助手以及實時反饋的人性化得分。
MagicPublish.ai是一個專注於為YouTube影片內容建立者提供中繼資料生成服務的線上平臺。它透過自動化的方式幫助使用者生成影片描述、標籤和縮圖,從而提升影片的SEO最佳化和觀眾吸引力。產品的主要優點包括操作簡便、自動化程度高、能夠顯著提升影片的線上可見度。
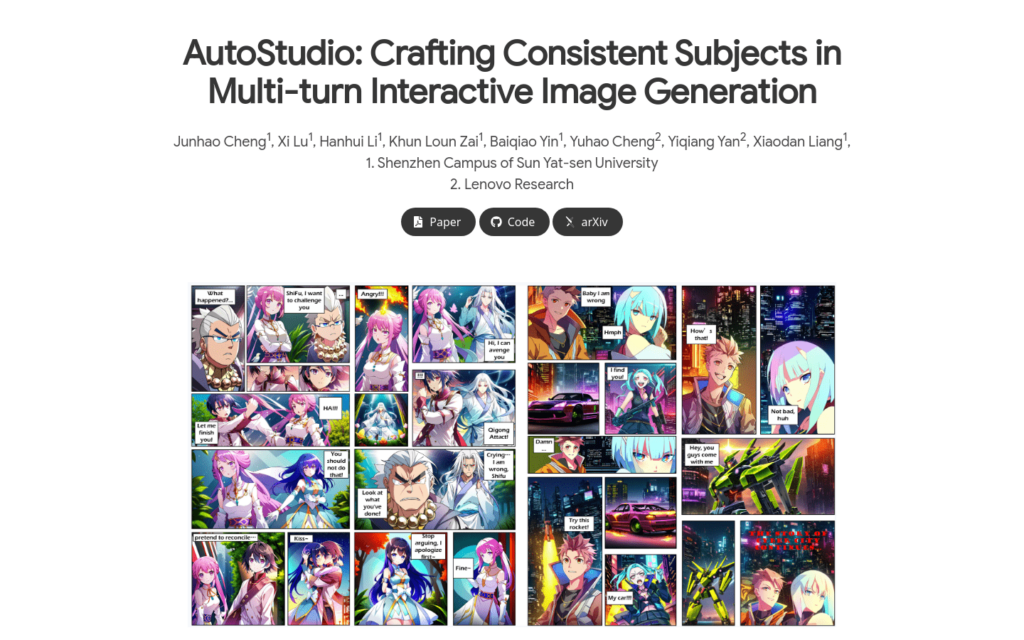
AutoStudio是一個基於大型語言模型的多輪互動式影象生成框架,它透過三個代理與一個基於穩定擴散的代理來生成高質量影象。該技術在多主題一致性方面取得了顯著進步,透過並行UNet結構和主題初始化生成方法,提高了影象生成的質量和一致性。