Pile-T5:基於Pile資料集訓練的T5模型
Pile-T5是EleutherAI推出的一款自然語言處理模型,它在原有的T5模型基礎上,採用了Pile資料集和LLAMA分詞器進行訓練,以改善對程式碼任務的理解能力。該模型經過了2萬億個token的訓練,是原T5模型訓練量的兩倍。Pile-T5在多項下游任務中表現出色,尤其是在程式碼相關任務上。

Pile-T5是EleutherAI推出的一款自然語言處理模型,它在原有的T5模型基礎上,採用了Pile資料集和LLAMA分詞器進行訓練,以改善對程式碼任務的理解能力。該模型經過了2萬億個token的訓練,是原T5模型訓練量的兩倍。Pile-T5在多項下游任務中表現出色,尤其是在程式碼相關任務上。
Llama中文社群是一個專注於Llama模型在中文方面的最佳化和上層建設的技術社群。社群提供基於大規模中文資料的預訓練模型,並對Llama2和Llama3模型進行持續的中文能力迭代升級。社群擁有高階工程師團隊支援,豐富的社群活動,以及開放共享的合作環境,旨在推動中文自然語言處理技術的發展。
Virtuoso QA是一款集自然語言程式設計(NLP)和機器人流程自動化(RPA)於一體的QA自動化測試工具,具有自愈式和可擴充套件性,可實現快速部署。
DataDreamer是一個強大的開源Python庫,用於提示、生成合成資料和訓練工作流。它旨在簡單易用,極其高效,且具有研究級質量。DataDreamer支援建立提示工作流、生成合成資料集、對齊模型、微調模型、指令調優模型和模型蒸餾。它具有簡單、研究級、高效、可復現的特點,並簡化了資料集和模型的共享。
minbpe專案旨在為LLM中常用的BPE演演算法建立乾淨、教育性的程式碼實現。該專案提供了兩種Tokenizer,實現了BPE演演算法的訓練、編碼、解碼等主要功能,程式碼簡潔易讀,為使用者提供便捷高效的使用體驗。該專案展現出巨大的關注度和吸引力,相信其會對LLM和自然語言處理技術的發展起到重要作用。
SpacTor是一種新的訓練程式,包括(1)結合了段落破壞(SC)和標記替換檢測(RTD)的混合目標,以及(2)一個兩階段課程,該課程在初始tau次迭代中最佳化混合目標,然後過渡到標準的SC損失。我們在多種NLP任務上進行了實驗,使用編碼器-解碼器架構(T5),SpacTor-T5在下游效能方面與標準的SC預訓練相當,同時減少了50%的預訓練迭代次數和40%的總FLOPs。另外,在相同的計算預算下,我們發現SpacTor能夠顯著提高下游基準效能。
Stable Diffusion XL是在 TPUv5e 上執行的一個 Hugging Face Space,它提供了穩定擴散 XL 模型的應用。Stable Diffusion XL是一個強大的自然語言處理模型,它在文字生成、問答、語義理解等多個領域有廣泛的應用。該模型在 TPUv5e 上執行,具有高效、穩定的特性,能夠處理大規模資料和複雜任務。
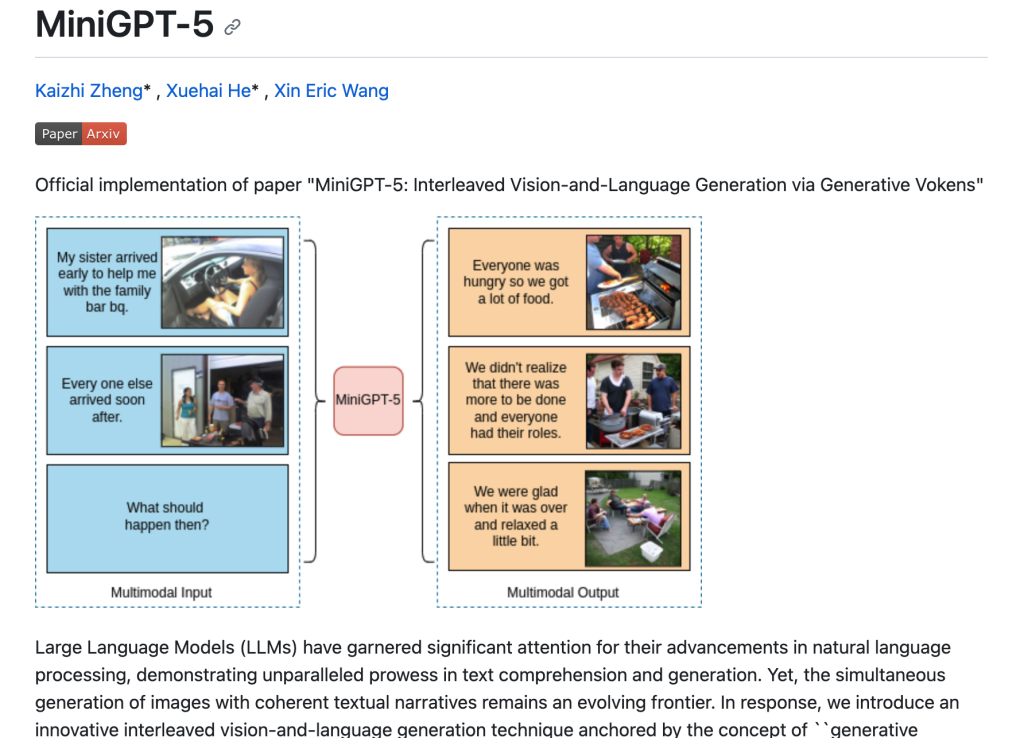
MiniGPT-5是一個基於生成式vokens的交錯式視覺語言生成技術,能夠同時生成文字敘述和相關的影象。它採用兩階段訓練策略,第一階段進行無描述的多模態生成訓練,第二階段進行多模態學習。該模型在多模態對話生成任務上取得了良好效果。
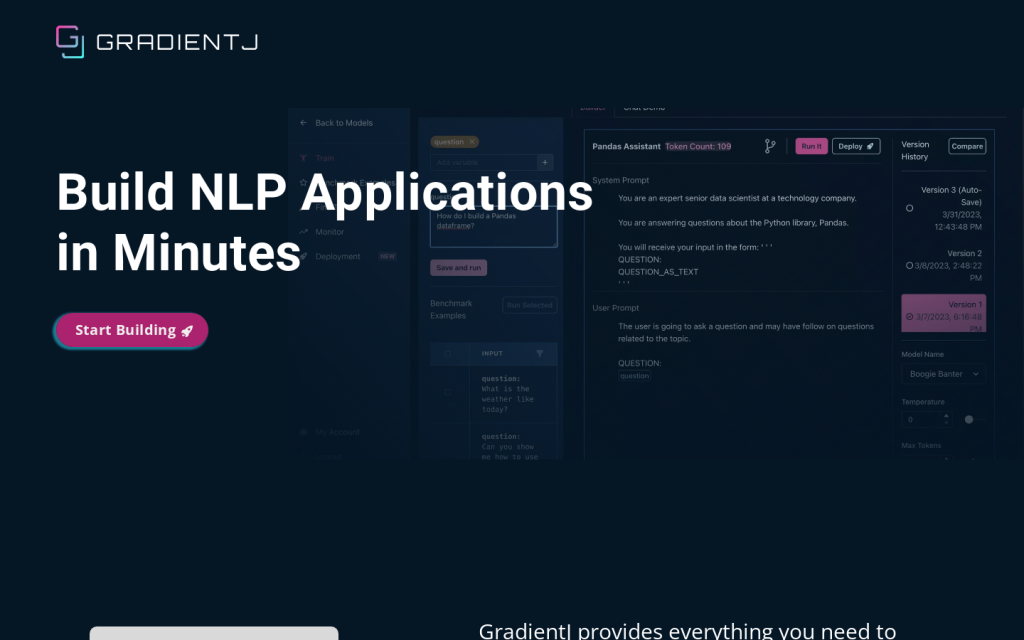
GradientJ是一個用於測試、部署和管理自然語言處理應用的平臺。它基於大型語言模型如GPT-4,提供快速構建NLP應用的能力。使用者可以使用GradientJ開發自定義的文字生成、問答系統、聊天機器人等NLP應用。GradientJ提供簡單易用的介面和工具,讓開發者能夠快速上手並實現自己的用例。定價方案靈活,適合個人開發者和企業使用者。