Index-1.9B-Chat:基於19億引數的對話生成模型
Index-1.9B-Chat是一個基於19億引數的對話生成模型,它透過SFT和DPO對齊技術,結合RAG實作fewshots角色扮演定製,具有較高的對話趣味性和定製性。該模型在2.8T中英文為主的語料上預訓練,並且在多個評測基準上表現領先。
Index-1.9B-Chat是一個基於19億引數的對話生成模型,它透過SFT和DPO對齊技術,結合RAG實作fewshots角色扮演定製,具有較高的對話趣味性和定製性。該模型在2.8T中英文為主的語料上預訓練,並且在多個評測基準上表現領先。

Qwen2是一系列經過預訓練和指令調整的模型,支援多達27種語言,包括英語和中文。這些模型在多個基準測試中表現出色,特別是在編碼和數學方面有顯著提升。Qwen2模型的上下文長度支援高達128K個token,適用於處理長文本任務。
GLM-4V-9B是智譜AI推出的新一代預訓練模型,支援1120*1120高解析度下的中英雙語多輪對話,以及視覺理解能力。在多模態評測中,GLM-4V-9B展現出超越GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max和Claude 3 Opus的卓越效能。
GLM-4-9B-Chat-1M 是智譜 AI 推出的新一代預訓練模型,屬於 GLM-4 系列的開源版本。它在語義、數學、推理、程式碼和知識等多方面的資料集測評中展現出較高的效能。該模型不僅支援多輪對話,還具備網頁瀏覽、程式碼執行、自訂工具呼叫和長文本推理等高階功能。
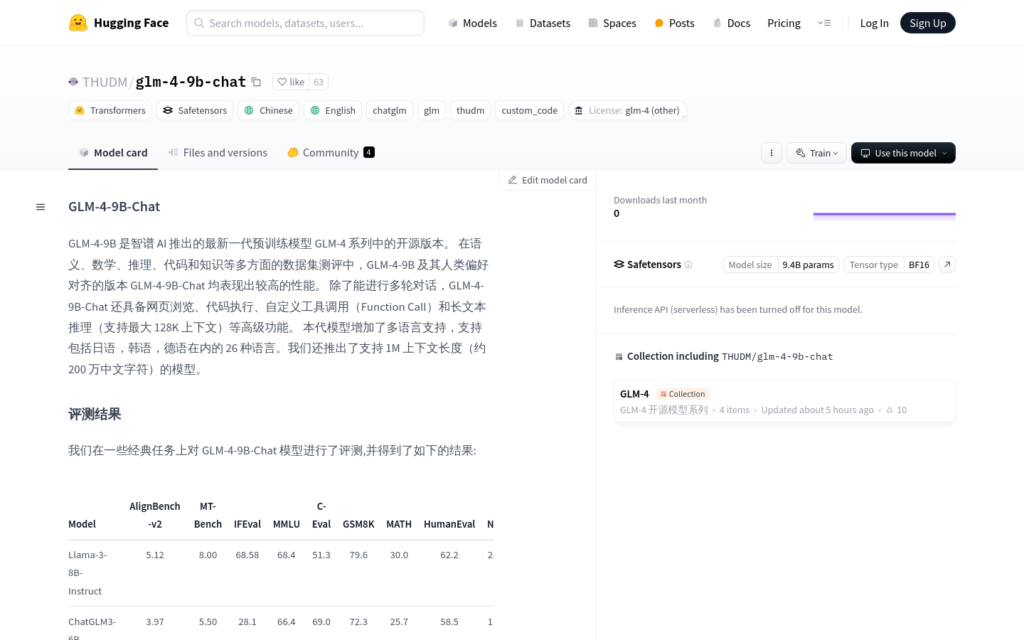
GLM-4-9B-Chat是智譜AI推出的新一代預訓練模型GLM-4系列中的開源版本,具備多輪對話、網頁瀏覽、程式碼執行、自訂工具呼叫和長文本推理等高階功能。支援包括日語、韓語、德語在內的26種語言,並且推出了支援1M上下文長度的模型。
TinyLlama專案旨在在3萬億令牌上預訓練一個1.1B Llama模型。透過一些適當的最佳化,我們可以在“僅”90天內使用16個A100-40G GPU完成。訓練已於2023-09-01開始。我們採用了與Llama 2完全相同的架構和分詞器。這意味著TinyLlama可以在許多建立在Llama基礎上的開源專案中使用。此外,TinyLlama只有1.1B個引數,緊湊性使其能夠滿足許多對計算和記憶體佔用有限的應用需求。

Yi是一款全球領先的預訓練模型,在多項評測中取得了SOTA國際最佳效能指標表現。它具有輕巧的模型尺寸,超越了大尺寸開源模型,更加友好於開發者社群。零一萬物適合個人及研究用途,並且已具備大模型湧現能力,適用於多元場景,滿足開源社區的剛性需求。Yi開源模型對學術研究完全開放,並且同步開放免費商用申請。
Gemma-2b是谷歌推出的開源預訓練語言模型系列,提供了多個不同規模的變體。它可以生成高質量的文字,廣泛應用於問答、摘要、推理等領域。相比其他同類模型,它模型規模較小,可以部署在不同的硬體環境中。Gemma系列追求安全、高效的人工智慧技術,使更多研究者和開發者可以接觸前沿的語言模型技術。
SpacTor是一種新的訓練程式,包括(1)結合了段落破壞(SC)和標記替換檢測(RTD)的混合目標,以及(2)一個兩階段課程,該課程在初始tau次迭代中最佳化混合目標,然後過渡到標準的SC損失。我們在多種NLP任務上進行了實驗,使用編碼器-解碼器架構(T5),SpacTor-T5在下游效能方面與標準的SC預訓練相當,同時減少了50%的預訓練迭代次數和40%的總FLOPs。另外,在相同的計算預算下,我們發現SpacTor能夠顯著提高下游基準效能。