DigiRL:使用自主強化學習訓練野外設備控制代理
DigiRL是一個創新的線上強化學習演算法,用於訓練能夠在野外環境中控制設備的智慧代理。它透過自主價值評估模型(VLM)來解決開放式的、現實世界中的Android任務。DigiRL的主要優點包括能夠利用現有的非最優離線資料集,並透過離線到線上的強化學習來鼓勵代理從自身的嘗試和錯誤中學習。
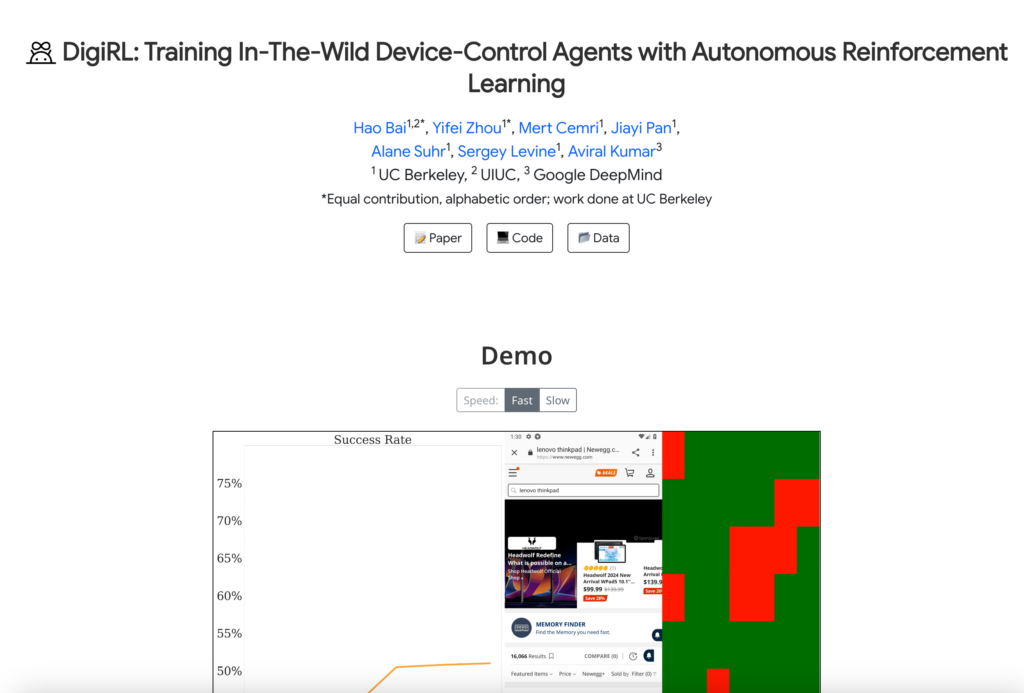
DigiRL是一個創新的線上強化學習演算法,用於訓練能夠在野外環境中控制設備的智慧代理。它透過自主價值評估模型(VLM)來解決開放式的、現實世界中的Android任務。DigiRL的主要優點包括能夠利用現有的非最優離線資料集,並透過離線到線上的強化學習來鼓勵代理從自身的嘗試和錯誤中學習。
RL4VLM是一個開源專案,旨在透過強化學習微調大型視覺-語言模型,使其成為能夠做出決策的智慧代理。該專案由Yuexiang Zhai, Hao Bai, Zipeng Lin, Jiayi Pan, Shengbang Tong, Alane Suhr, Saining Xie, Yann LeCun, Yi Ma, Sergey Levine等研究人員共同開發。
DIAMOND(DIffusion As a Model Of eNvironment Dreams)是一個在擴散世界模型中訓練的強化學習代理,用於雅達利遊戲中的視覺細節至關重要的世界建模。它透過自迴歸想象在Atari遊戲子集上進行訓練,可以快速安裝並嘗試預先訓練的世界模型。
Parrot 是一種多目標強化學習框架,專為文字轉影象生成而設計。它透過批次 Pareto 最優選擇的方式,自動識別在 T2I 生成的 RL 最佳化過程中不同獎勵之間的最佳權衡。此外,Parrot採用了 T2I 模型和提示擴充套件網路的聯合最佳化方法,促進了生成質量感知的文字提示,從而進一步提高了最終影象質量。為了抵消由於提示擴充套件而可能導致的原始使用者提示的潛在災難性遺忘,我們在推理時引入了原始提示中心化指導,確保生成的影象忠實於使用者輸入。大量實驗和使用者研究表明,Parrot在各種質量標準,包括美學、人類偏好、影象情感和文字-影象對齊方面,均優於幾種基線方法。

Starling-7B 是一個由強化學習從 AI 反饋(RLAIF)訓練的開放大型語言模型(LLM)。它透過我們的新 GPT-4 標記排序資料集 Nectar 和新的獎勵訓練和策略調優流程充分發揮了作用。Starling-7B 在使用 GPT-4 作為評委的 MT Bench 中得分為 8.09,在 MT-Bench 上超過了目前所有模型,除了 OpenAI 的 GPT-4 和 GPT-4 Turbo。我們在 HuggingFace 上釋出了排名資料集 Nectar、獎勵模型 Starling-RM-7B-alpha 和語言模型 Starling-LM-7B-alpha,以及 LMSYS Chatbot Arena 中的線上演示。請期待我們即將釋出的程式碼和論文,其中將提供有關整個過程的更多詳細資訊。

Eureka是一種人類級獎勵設計演算法,透過編碼大型語言模型實現。它利用最先進的語言模型(如GPT-4)的零樣本生成、編寫程式碼和上下文改進能力,對獎勵程式碼進行進化最佳化。生成的獎勵可以用於透過強化學習獲得複雜的技能。Eureka生成的獎勵函式在29個開源強化學習環境中,包括10種不同的機器人形態,優於人類專家設計的獎勵函式。Eureka還能夠靈活地改進獎勵函式,以提高生成獎勵的質量和安全性。透過與課程學習相結合,使用Eureka獎勵函式,我們首次展示了一個模擬的Shadow Hand能夠進行旋轉筆的技巧,熟練地以快速的速度在圓圈中操縱筆。

SERL是一個經過精心實現的程式碼庫,包含了一個高效的離策略深度強化學習方法,以及計算獎勵和重置環境的方法,一個高質量的廣泛採用的機器人控制器,以及一些具有挑戰性的示例任務。它為社區提供了一個資源,描述了它的設計選擇,並呈現了實驗結果。令人驚訝的是,我們發現我們的實現可以實現非常高效的學習,僅需25到50分鐘的訓練即可獲得PCB裝配、電纜佈線和物體重定位等策略,改進了文獻中報告的類似任務的最新結果。這些策略實現了完美或接近完美的成功率,即使在擾動下也具有極強的魯棒性,並呈現出新興的恢復和修正行為。我們希望這些有前途的結果和我們的高質量開源實現能為機器人社區提供一個工具,以促進機器人強化學習的進一步發展。