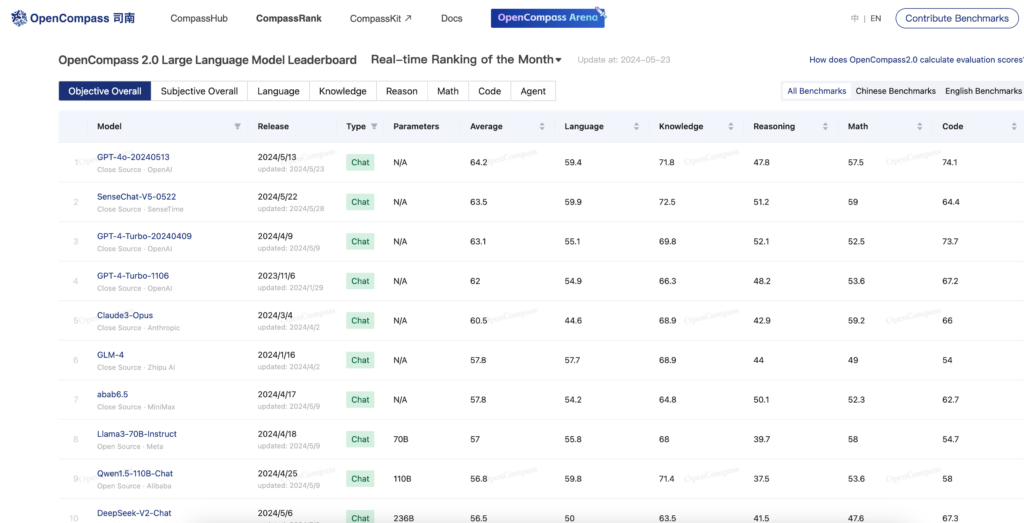
連結:https://rank.opencompass.org.cn/leaderboard-llm
OpenCompass 2.0是一個專注於大型語言模型效能評估的平臺。它使用多個閉源資料集進行多維度評估,為模型提供整體平均分和專業技能分數。該平臺透過實時更新排行榜,幫助開發者和研究人員瞭解不同模型在語言、知識、推理、數學和程式設計等方面的效能表現。
需求人群:
該產品適合研究人員、開發者和企業決策者,他們需要評估和比較不同大型語言模型的效能,以便選擇最適合自己專案的模型。
使用場景示例:
研究人員使用OpenCompass 2.0評估不同模型在特定任務上的表現。
開發者利用排行榜選擇適合開發聊天機器人的語言模型。
企業決策者根據排行榜資料決定採用哪種模型來最佳化其產品。
產品特色:
多維度評估模型效能:語言、知識、推理、數學和程式設計。
實時更新排行榜,展示最新模型效能。
提供模型在不同資料集上的詳細評分。
支援檢視模型設定檔,瞭解評分背後的技術細節。
閉源資料集確保評估的公正性和權威性。
使用者可以輕鬆導覽到GitHub檢視相關設定檔。
使用教學:
訪問OpenCompass 2.0的官方網站。
檢視實時更新的大型語言模型排行榜。
選擇感興趣的模型,檢視其在不同維度上的評分。
點選評分,導覽到GitHub檢視模型的設定檔。
根據設定檔和技術細節,評估模型是否適合自己的需求。
參考排行榜和案例,做出選擇或進一步研究。