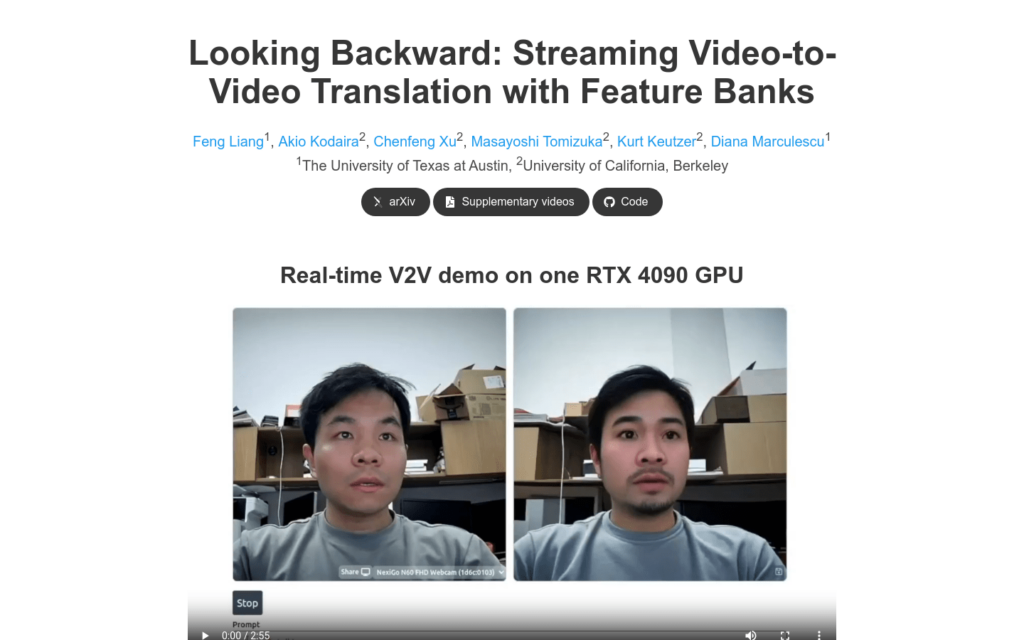
連結:https://jeff-liangf.github.io/projects/streamv2v/
StreamV2V是一個擴散模型,它透過使用者提示實作了實時的影片到影片(V2V)翻譯。與傳統的批處理方法不同,StreamV2V採用流式處理方式,能夠處理無限幀的影片。它的核心是維護一個特徵庫,該庫儲存了過去幀的資訊。對於新進來的幀,StreamV2V透過擴充自注意力和直接特徵融合技術,將相似的過去特徵直接融合到輸出中。特徵庫透過合併儲存的和新的特徵不斷更新,保持緊湊且資訊豐富。StreamV2V以其適應性和效率脫穎而出,無需微調即可與影象擴散模型無縫整合。
需求人群:
StreamV2V適用於需要實時影片處理和翻譯的專業人士和研究人員。它特別適用於影片編輯、電影后期製作、實時影片增強和虛擬實境等領網網域,因為它能夠提供快速、無縫的影片處理能力,同時保持高質量的輸出。
使用場景示例:
- 影片編輯師使用StreamV2V實時調整影片風格和效果。
- 電影后期製作團隊利用StreamV2V進行特效的實時預覽和調整。
- 虛擬實境開發者使用StreamV2V為VR體驗提供實時影片內容的動態調整。
產品特色:
- 實時影片到影片翻譯:支援無限幀的影片處理。
- 使用者提示:允許使用者輸入指令以指導影片翻譯。
- 特徵庫維護:儲存過去幀的中間變換器特徵。
- 擴充自注意力(EA):將儲存的鍵和值直接連線到當前幀的自注意力計算中。
- 直接特徵融合(FF):透過餘弦相似性矩陣檢索銀行中的相似特徵,並進行加權求和融合。
- 高效率:在單個A100 GPU上執行速度為20 FPS,比FlowVid、CoDeF、Rerender和TokenFlow快15倍、46倍、108倍和158倍。
- 優異的時間一致性:透過定量指標和使用者研究確認。
使用教學:
- 步驟1:訪問StreamV2V的官方網站。
- 步驟2:閱讀有關模型的介紹和功能。
- 步驟3:根據需要設定使用者提示,指導影片翻譯的方向。
- 步驟4:上傳或連線需要翻譯的影片源。
- 步驟5:啟動StreamV2V模型,開始實時影片翻譯。
- 步驟6:觀察翻譯過程中的影片輸出,並根據需要調整引數。
- 步驟7:完成翻譯後,下載或直接使用翻譯後的影片內容。