Imagine Flash:使用極少步驟生成高保真、多樣化樣本
Imagine Flash 是一種新型的擴散模型,它透過後向蒸餾框架,使用僅一到三個步驟就能實作高保真、多樣化的樣本生成。該模型包含三個關鍵元件:後向蒸餾、動態適應的知識轉移以及噪音校正技術,顯著提升了在極低步驟情況下的影象質量和樣本多樣性。
Imagine Flash 是一種新型的擴散模型,它透過後向蒸餾框架,使用僅一到三個步驟就能實作高保真、多樣化的樣本生成。該模型包含三個關鍵元件:後向蒸餾、動態適應的知識轉移以及噪音校正技術,顯著提升了在極低步驟情況下的影象質量和樣本多樣性。
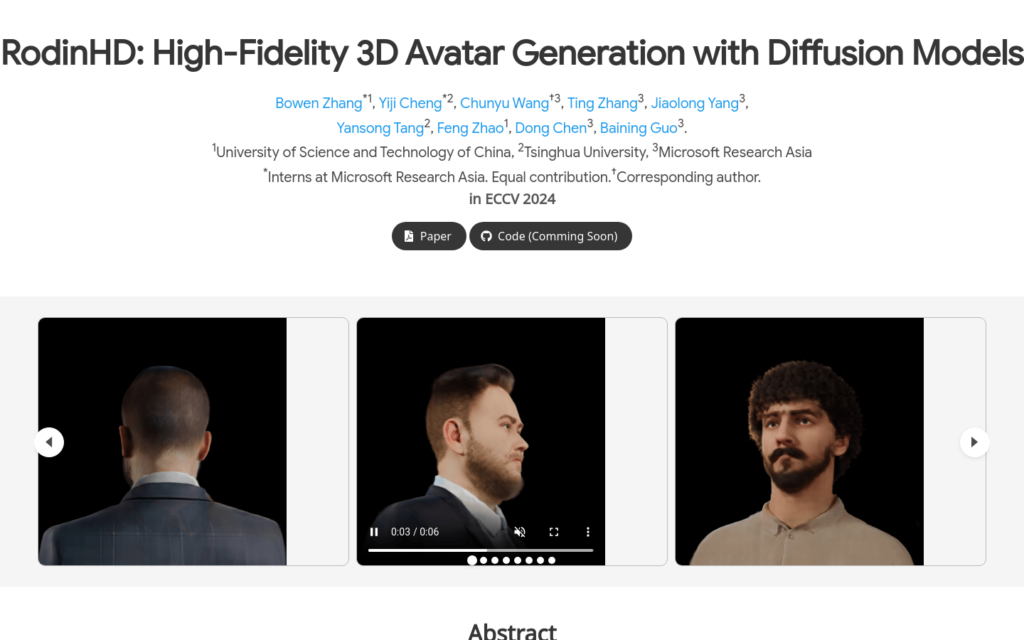
RodinHD是一個基於擴散模型的高保真3D頭像生成技術,由Bowen Zhang、Yiji Cheng等研究者開發,旨在從單一肖像影象生成細節豐富的3D頭像。該技術解決了現有方法在捕捉髮型等複雜細節時的不足,透過新穎的資料排程策略和權重整合正則化項,提高瞭解碼器渲染銳利細節的能力。

Flash Diffusion 是一種高效的影象生成模型,透過少步驟生成高質量的影象,適用於多種影象處理任務,如文本到影象、修復、超解析度等。該模型在 COCO2014 和 COCO2017 資料集上達到了最先進的效能,同時訓練時間少,引數數量少。
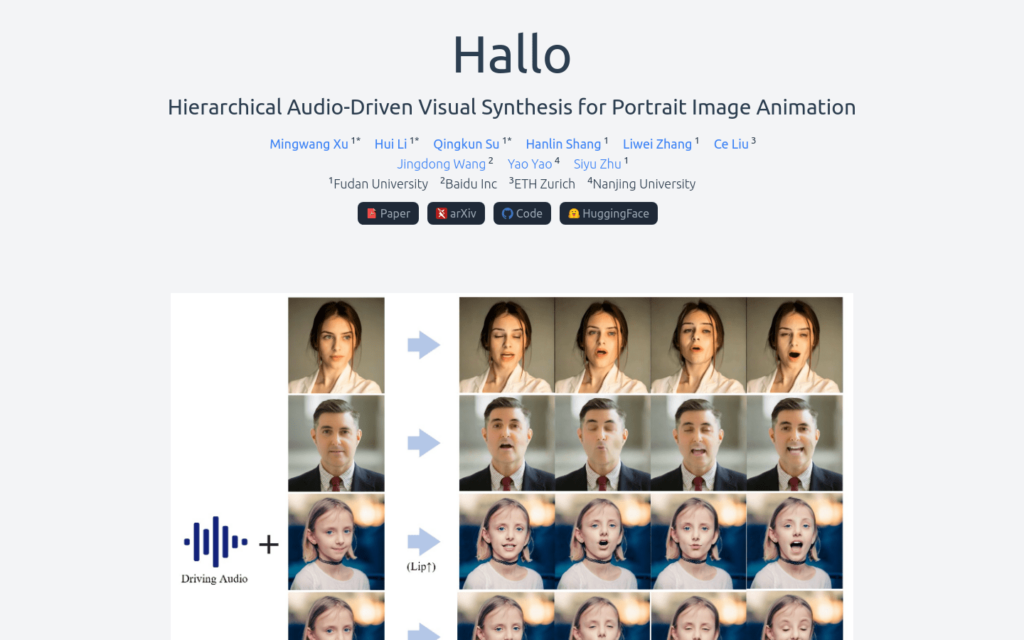
Hallo是一個由復旦大學開發的肖像影象動畫技術,它利用擴散模型生成逼真且動態的肖像動畫。與傳統依賴引數模型的中間面部表示不同,Hallo採用端到端的擴散範式,並引入了一個分層的音訊驅動視覺合成模組,以增強音訊輸入和視覺輸出之間的對齊精度,包括嘴唇、表情和姿態運動。
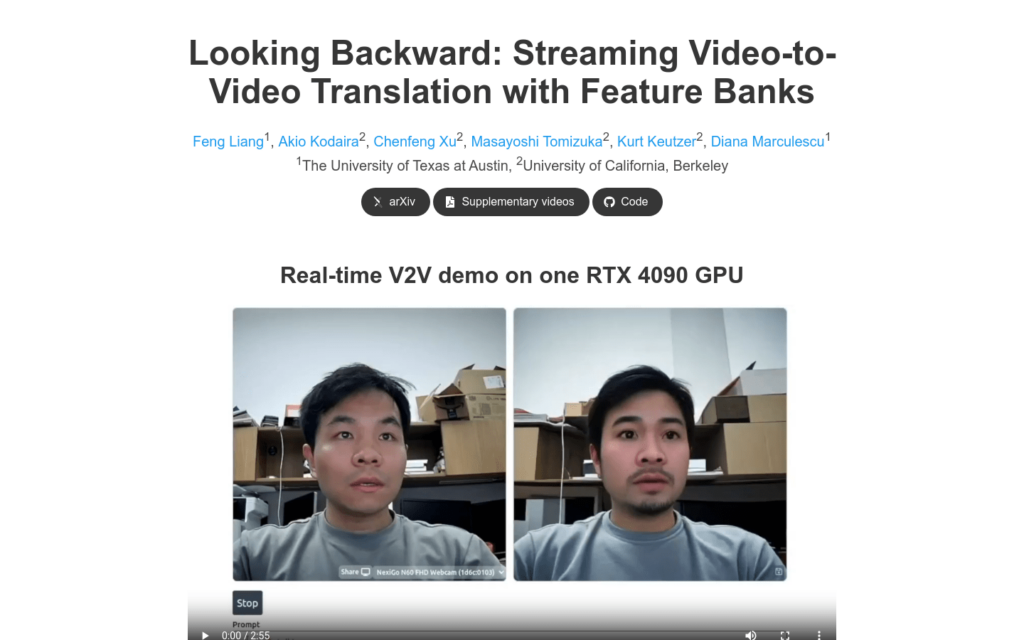
StreamV2V是一個擴散模型,它透過使用者提示實作了實時的影片到影片(V2V)翻譯。與傳統的批處理方法不同,StreamV2V採用流式處理方式,能夠處理無限幀的影片。它的核心是維護一個特徵庫,該庫儲存了過去幀的資訊。對於新進來的幀,StreamV2V透過擴充自注意力和直接特徵融合技術,將相似的過去特徵直接融合到輸出中。特徵庫透過合併儲存的和新的特徵不斷更新,保持緊湊且資訊豐富。StreamV2V以其適應性和效率脫穎而出,無需微調即可與影象擴散模型無縫整合。

Make-An-Audio 2是一種基於擴散模型的文本到音訊生成技術,該技術透過使用預訓練的大型語言模型(LLMs)解析文本,最佳化了語義對齊和時間一致性,提高了生成音訊的質量。它還設計了基於前饋Transformer的擴散去噪器,以改善變長音訊生成的效能,並增強時間資訊的提取。

AnyDoor AI是一款突破性的影象生成工具,其設計理念基於擴散模型。它可以無縫地將目標物體嵌入到使用者指定的新場景位置。AnyDoor從本質上重新定義了影象操作,承諾在日常互動中提供多種更人性化的應用。
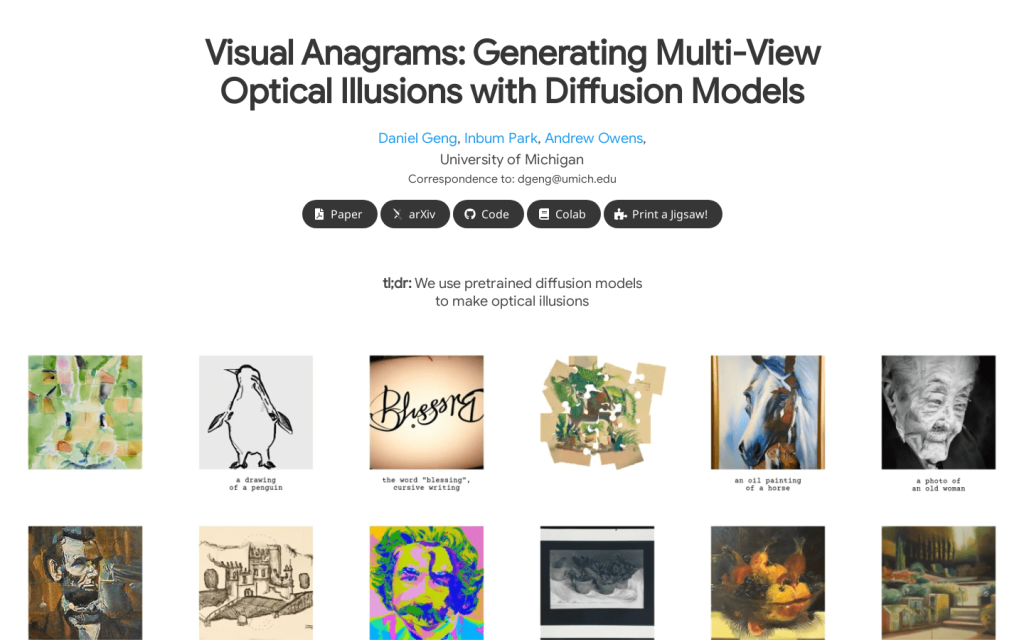
Visual Anagrams是一種簡單的、零樣本方法,用於生成多視角視覺錯覺。我們展示了理論和實踐證明,我們的方法支援廣泛的變換,包括旋轉、翻轉、顏色反轉、傾斜、拼圖重排和隨機排列等。我們的方法使用預訓練擴散模型來估計影象的不同視角或變換中的噪聲,並將其對齊並平均。然後使用這個平均噪聲估計來進行擴散步驟。使用Visual Anagrams,您可以製作出多種多視角視覺錯覺。
Civitai 是一個穩定的擴散 AI 藝術模型平臺。瀏覽數千個模型,並與不斷增長的創作者社區互動,分享圖片和提示。加入一個積極參與的社區,共同評審模型並分享創作靈感。
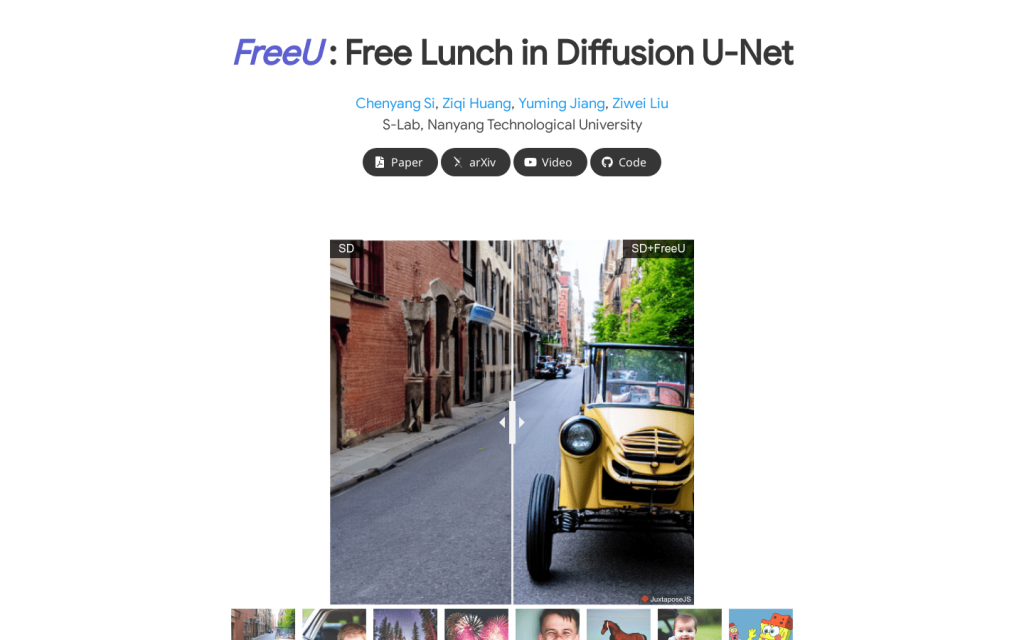
FreeU是一種方法,可以在不增加成本的情況下顯著提高擴散模型的取樣質量:無需訓練,無需引入額外引數,無需增加記憶體或取樣時間。該方法透過重新加權U-Net的跳躍連線和主幹特徵圖的貢獻,結合U-Net架構的兩個組成部分的優勢,從而提高生成質量。透過在影象和影片生成任務上進行實驗,我們證明了FreeU可以輕鬆整合到現有的擴散模型中,例如Stable Diffusion、DreamBooth、ModelScope、Rerender和ReVersion,只需幾行程式碼即可改善生成質量。