MOFA-Video:透過生成運動場適應實作單影象動畫化
MOFA-Video是一種能夠將單張圖片透過各種控制訊號動畫化的方法。它採用了稀疏到密集(S2D)運動生成和基於流的運動適應技術,可以有效地使用軌跡、關鍵點序列及其組合等不同型別的控制訊號來動畫化單張圖片。在訓練階段,透過稀疏運動取樣生成稀疏控制訊號,然後訓練不同的MOFA-Adapters來透過預訓練的SVD生成影片。在推理階段,不同的MOFA-Adapters可以組合起來共同控制凍結的SVD。
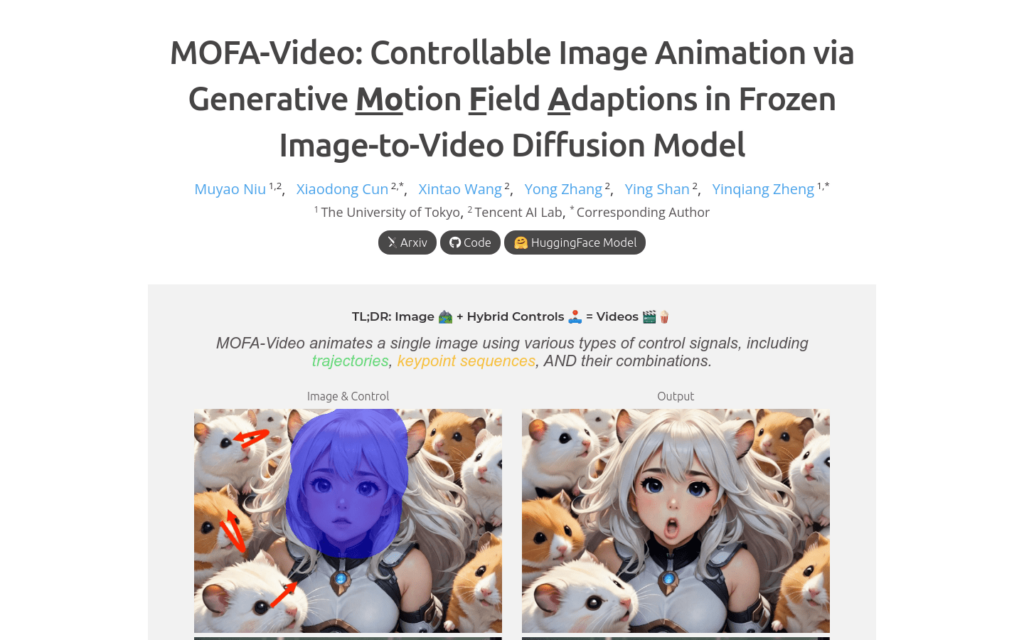
MOFA-Video是一種能夠將單張圖片透過各種控制訊號動畫化的方法。它採用了稀疏到密集(S2D)運動生成和基於流的運動適應技術,可以有效地使用軌跡、關鍵點序列及其組合等不同型別的控制訊號來動畫化單張圖片。在訓練階段,透過稀疏運動取樣生成稀疏控制訊號,然後訓練不同的MOFA-Adapters來透過預訓練的SVD生成影片。在推理階段,不同的MOFA-Adapters可以組合起來共同控制凍結的SVD。
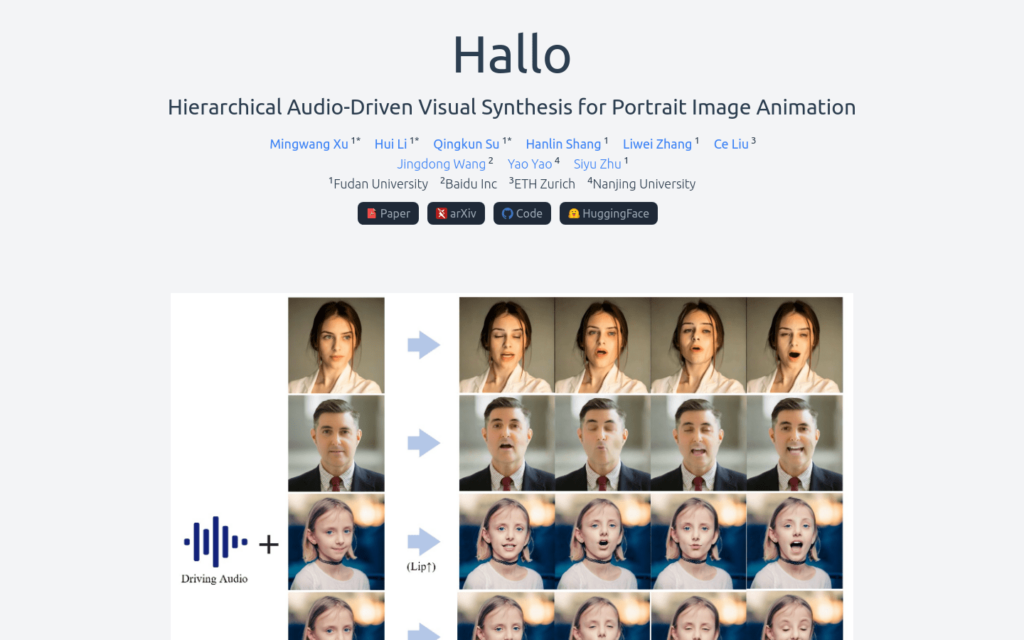
Hallo是一個由復旦大學開發的肖像影象動畫技術,它利用擴散模型生成逼真且動態的肖像動畫。與傳統依賴引數模型的中間面部表示不同,Hallo採用端到端的擴散範式,並引入了一個分層的音訊驅動視覺合成模組,以增強音訊輸入和視覺輸出之間的對齊精度,包括嘴唇、表情和姿態運動。
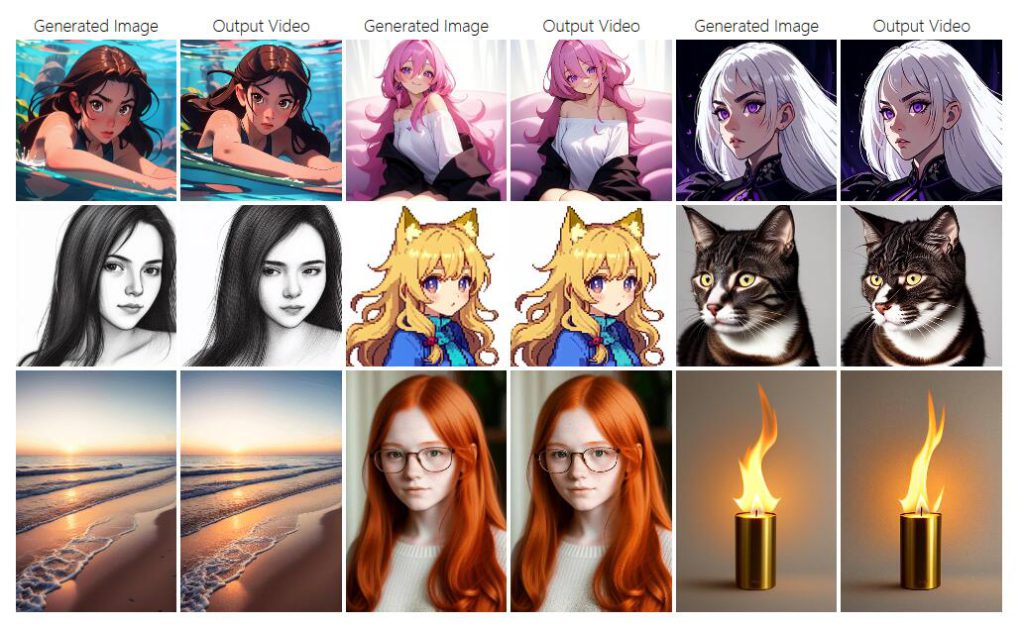
AnimateZero是一款零樣本影象動畫生成器,透過分離外觀和運動生成影片,解決了黑盒、低效、不可控等問題。它可以透過零樣本修改將預訓練的T2V模型轉換為I2V模型,從而實現零樣本影象動畫生成。AnimateZero還可以用於影片編輯、幀插值、循環影片生成和真實影象動畫等場景,具有較高的主觀質量和匹配度。