連結:https://fudan-generative-vision.github.io/hallo/
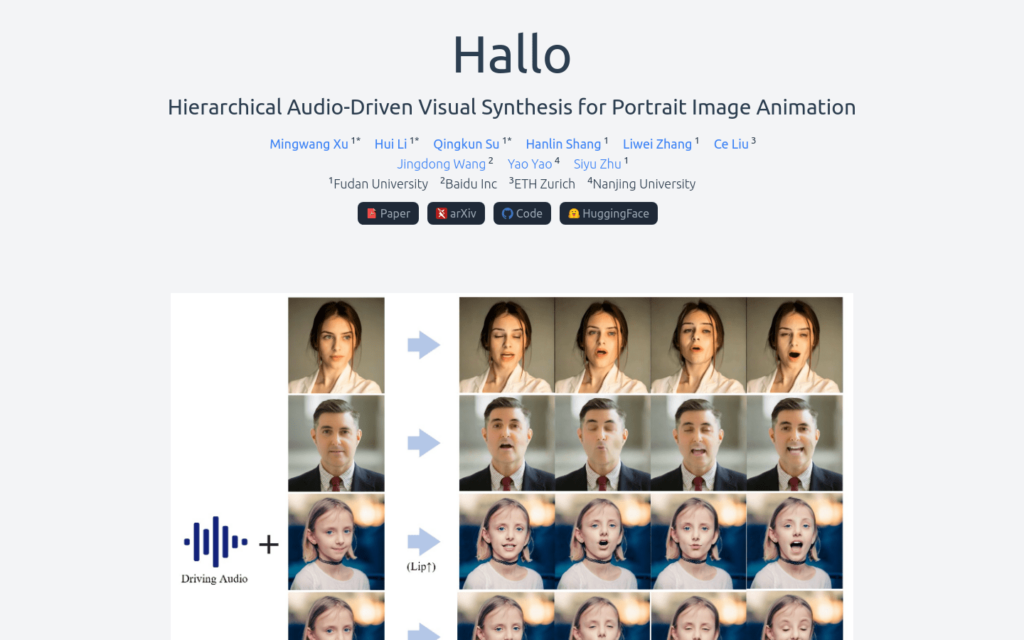
Hallo是一個由復旦大學開發的肖像影象動畫技術,它利用擴散模型生成逼真且動態的肖像動畫。與傳統依賴引數模型的中間面部表示不同,Hallo採用端到端的擴散範式,並引入了一個分層的音訊驅動視覺合成模組,以增強音訊輸入和視覺輸出之間的對齊精度,包括嘴唇、表情和姿態運動。該技術提供了對錶情和姿態多樣性的自適應控制,能夠更有效地實作個性化定製,適用於不同身份的人。
需求人群:
- Hallo技術適用於需要生成逼真動態肖像動畫的領網網域,如電影製作、遊戲開發、虛擬實境等。它特別適合那些尋求高度個性化和真實感的動畫效果的專業人士和創意團隊。
使用場景示例:
- 電影製作中,用於生成角色的逼真面部表情和口型。
- 遊戲開發中,為虛擬角色提供動態的面部動畫。
- 虛擬實境中,為使用者互動提供更加真實的面部反饋。
產品特色:
- 基於擴散模型的生成模型,用於建立逼真的肖像動畫。
- UNet基礎的去噪器,用於提高影象質量。
- 時間對齊技術,確保動畫與音訊輸入同步。
- 參考網路,用於改善面部動作的精確度。
- 分層音訊驅動視覺合成模組,增強音訊與視覺輸出的對齊。
- 自適應控制表情和姿態多樣性,實作個性化定製。
- 綜合評估,包括定性和定量分析,展示影象和影片質量、唇同步精度以及運動多樣性的提升。
使用教學:
訪問Hallo產品頁面。
瞭解產品介紹和技術背景。
檢視技術細節和主要功能點。
閱讀使用案例,瞭解產品在不同場景下的應用。
根據個人需求,選擇合適的功能進行嘗試。
參與社群討論,獲取技術支援和使用者反饋。
根據反饋調整使用策略,最佳化動畫效果。