AnimateZero:零樣本影象動畫生成器
AnimateZero是一款零樣本影象動畫生成器,透過分離外觀和運動生成影片,解決了黑盒、低效、不可控等問題。它可以透過零樣本修改將預訓練的T2V模型轉換為I2V模型,從而實現零樣本影象動畫生成。AnimateZero還可以用於影片編輯、幀插值、循環影片生成和真實影象動畫等場景,具有較高的主觀質量和匹配度。
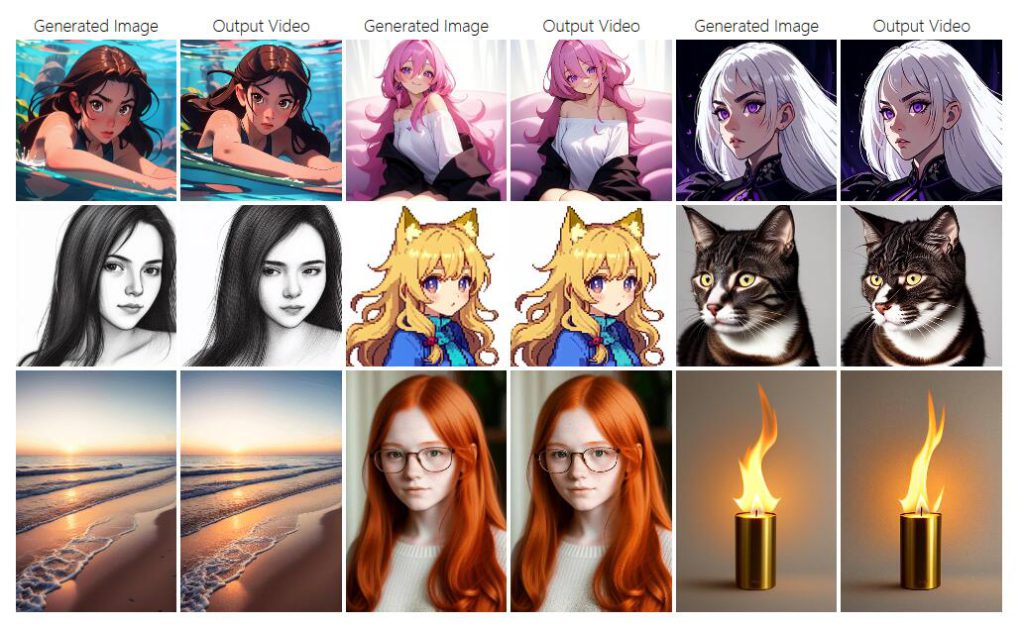
AnimateZero是一款零樣本影象動畫生成器,透過分離外觀和運動生成影片,解決了黑盒、低效、不可控等問題。它可以透過零樣本修改將預訓練的T2V模型轉換為I2V模型,從而實現零樣本影象動畫生成。AnimateZero還可以用於影片編輯、幀插值、循環影片生成和真實影象動畫等場景,具有較高的主觀質量和匹配度。
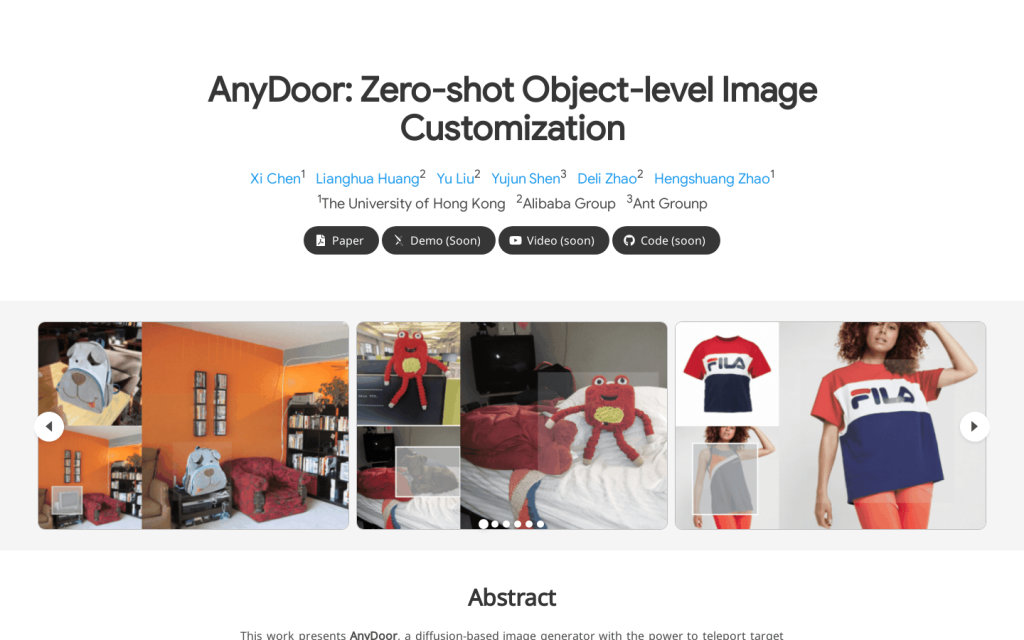
AnyDoor 是一種基於擴散的影象生成器,可以在使用者指定的位置將目標對象以和諧的方式傳送到新場景中。我們的模型只需要訓練一次,就可以輕鬆推廣到不同的對象和場景組合中,無需為每個對象調整引數。為了充分描述某個特定對象,我們除了使用常用的身份特徵外,還補充了細節特徵,這些特徵經過精心設計,既能保持紋理細節,又能允許多樣的區域性變化(如光照、方向、姿勢等),從而使對象與不同的環境更好地融合。我們還提出從影片資料集中借用知識的方法,在影片資料集中可以觀察到同一對象的各種形態(沿時間軸),從而增強模型的泛化能力和魯棒性。大量實驗證明了我們方法的優越性,以及它在虛擬試穿和物體移動等實際應用中的巨大潛力。
Binoculars是一個先進的AI生成文字檢測工具,無需訓練資料即可零配置使用。它的檢測思路非常簡單明瞭:大多數只用decoder的因果語言模型在預訓練時使用了大量相同的資料集,例如Common Crawl、Pile等。更多關於該方法及其效果的資訊請參閱我們的論文《用雙目鏡發現LLM: 機器生成文字的零樣本檢測》。