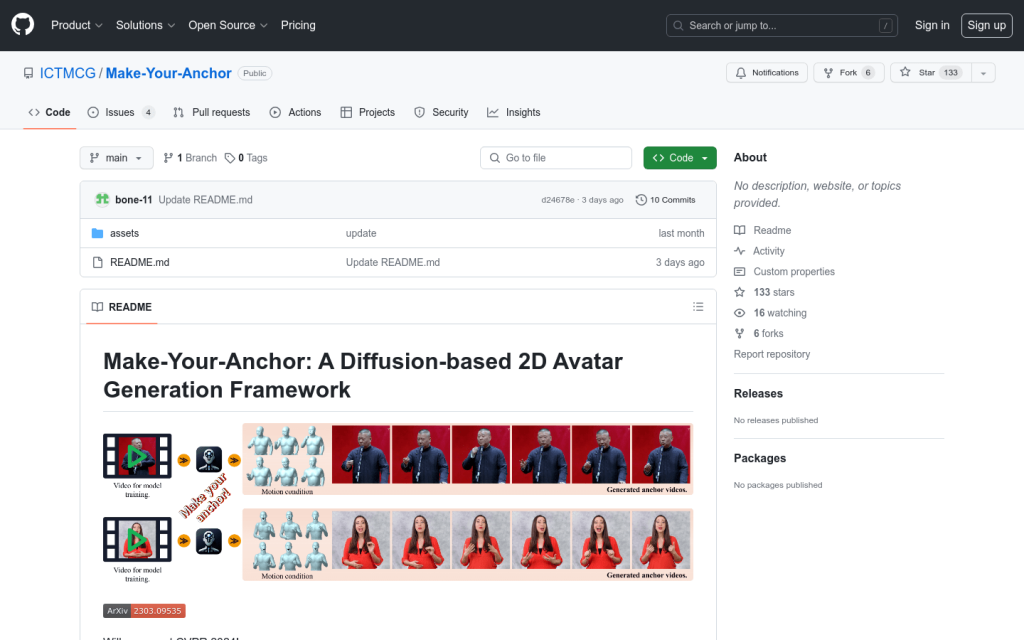
Make-Your-Anchor:基於擴散模型的2D虛擬形象生成框架
Make-Your-Anchor是一個基於擴散模型的2D虛擬形象生成框架。它只需一段1分鐘左右的影片素材就可以自動生成具有精確上身和手部動作的主播風格影片。該系統採用了一種結構引導的擴散模型來將3D網格狀態渲染成人物外觀。透過兩階段訓練策略,有效地將運動與特定外觀相繫結。為了生成任意長度的時序影片,將frame-wise擴散模型的2D U-Net擴充套件到3D形式,並提出簡單有效的批重疊時序去噪模組,從而突破推理時的影片長度限制。最後,引入了一種基於特定身份的面部增強模組,提高輸出影片中面部區域的視覺質量。實驗表明,該系統在視覺質量、時序一致性和身份保真度方面均優於現有技術。