OpenCompass司南 – 評測榜單:大型語言模型排行榜,實時評估模型效能
OpenCompass 2.0是一個專注於大型語言模型效能評估的平臺。它使用多個閉源資料集進行多維度評估,為模型提供整體平均分和專業技能分數。該平臺透過實時更新排行榜,幫助開發者和研究人員瞭解不同模型在語言、知識、推理、數學和程式設計等方面的效能表現。
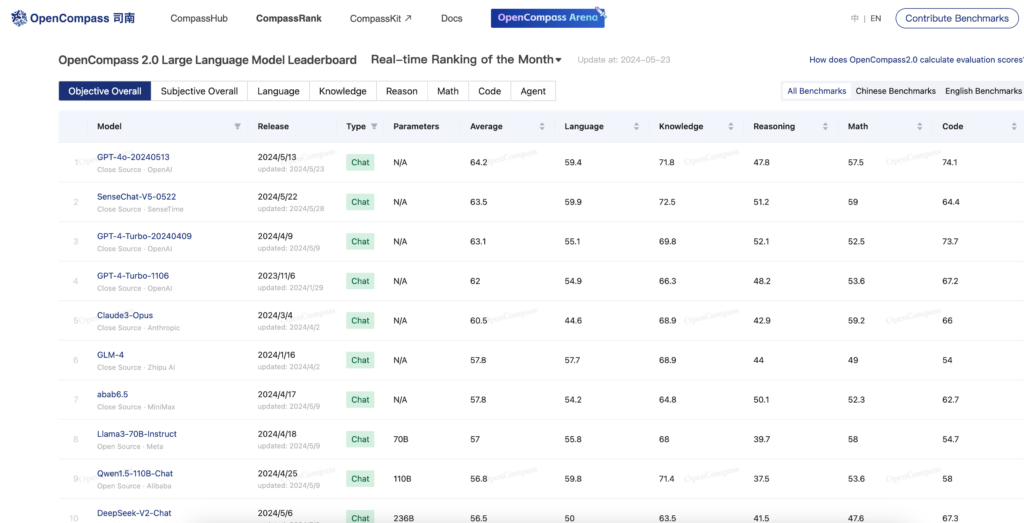
OpenCompass 2.0是一個專注於大型語言模型效能評估的平臺。它使用多個閉源資料集進行多維度評估,為模型提供整體平均分和專業技能分數。該平臺透過實時更新排行榜,幫助開發者和研究人員瞭解不同模型在語言、知識、推理、數學和程式設計等方面的效能表現。
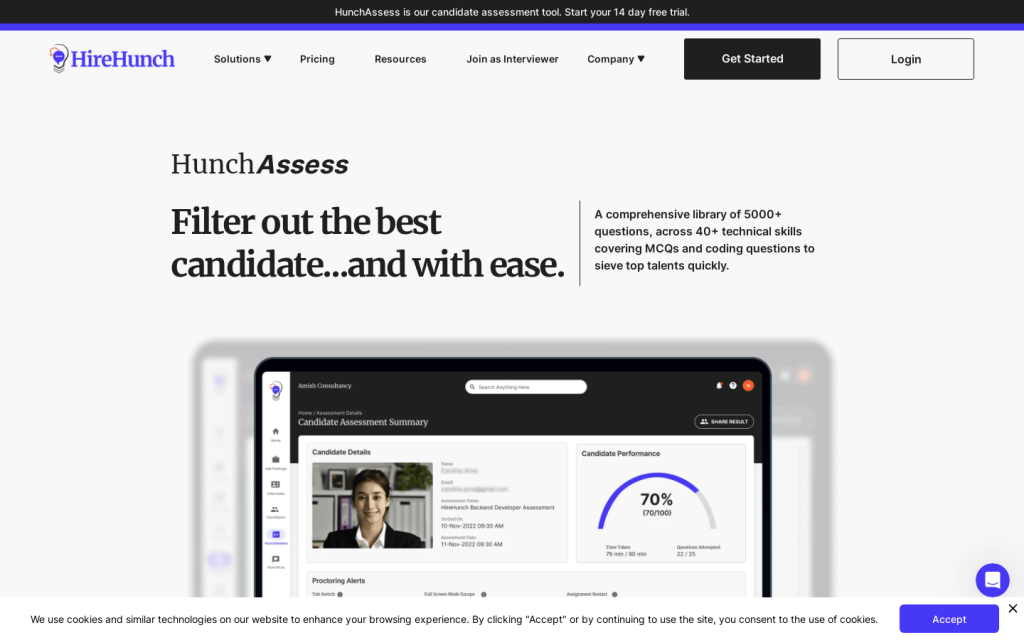
HunchAssess是HireHunch的候選人評估工具。它提供了一個全面的問題庫,包含5000多個問題,涵蓋40多種技術技能,包括多項選擇題和程式設計題,可以快速篩選頂尖人才。它支援批次傳送邀請,自動計分和高階監考功能,可以輕鬆地評估候選人的技能和專業知識。關鍵功能包括:預設的40多種技能集評估、批次傳送邀請、自動計分板和高階監考、安排面試等。適用於招聘機構或HR團隊進行校園招聘或大規模篩選應聘者。
PromptBench是一個基於Pytorch的Python包,用於評估大型語言模型(LLM)。它為研究人員提供了使用者友好的API,以便對LLM進行評估。主要功能包括:快速模型效能評估、提示工程、對抗提示評估以及動態評估等。優勢是使用簡單,可以快速上手評估已有資料集和模型,也可以輕鬆定製自己的資料集和模型。定位為LLM評估的統一開源庫。