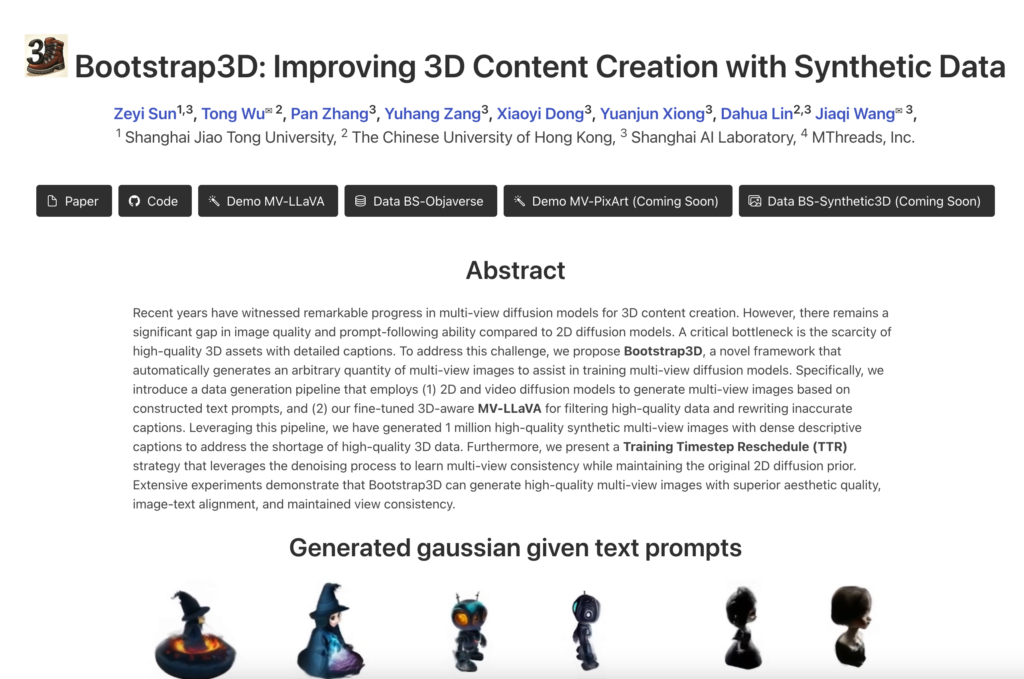
連結:https://sunzey.github.io/Bootstrap3D/
Bootstrap3D是一個用於改善3D內容創造的框架,透過合成資料生成技術,解決了高質量3D資產稀缺的問題。它利用2D和影片擴散模型,基於文本提示生成多視角影象,並使用3D感知的MV-LLaVA模型篩選高質量資料,重寫不準確的標題。該框架已生成了100萬張高質量合成多視角影象,具有密集的描述性標題,以解決高質量3D資料的短缺問題。此外,它還提出了一種訓練時間步重排(TTR)策略,利用去噪過程學習多視角一致性,同時保持原始的2D擴散先驗。
需求人群:
- Bootstrap3D適用於需要大量高質量3D資料進行訓練的研究人員和開發者,特別是在3D建模、虛擬實境和增強現實等領網網域。它可以幫助他們以較低的成本和更高效的方式生成所需的資料,從而推動3D內容創造技術的發展。
使用場景示例:
- 研究人員使用Bootstrap3D生成的多視角影象來訓練3D對象辨識模型
- 開發者利用該框架生成的資料來建立虛擬實境環境中的互動式3D對象
- 教育機構使用Bootstrap3D作為教學工具,教授學生如何使用合成資料來改進3D模型的訓練
產品特色:
- 自動生成任意數量的多視角影象以輔助訓練多視角擴散模型
- 使用2D和影片擴散模型基於文本提示生成多視角影象
- 透過MV-LLaVA模型篩選高質量資料並重寫標題
- 生成100萬張具有密集描述性標題的高質量合成多視角影象
- Training Timestep Reschedule (TTR)策略,利用去噪過程學習多視角一致性
- 生成的影象具有優越的審美質量、影象-文本對齊和保持視角一致性
使用教學:
1. 訪問Bootstrap3D網站並瞭解其功能和特點
2. 閱讀文檔以理解如何使用2D和影片擴散模型生成多視角影象
3. 根據需要編寫或選擇文本提示,以指導影象生成過程
4. 使用MV-LLaVA模型篩選和重寫生成的影象的標題
5. 應用TTR策略最佳化多視角影象的一致性和質量
6. 利用生成的高質量多視角影象進行3D內容創造或進一步的研究