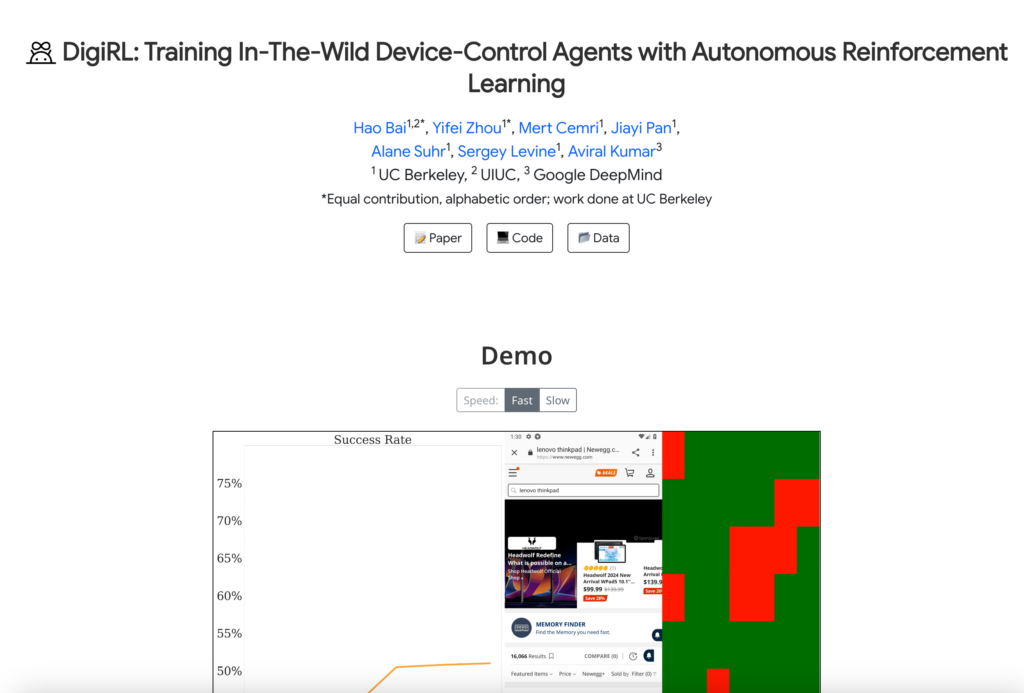
連結:https://digirl-agent.github.io/
DigiRL是一個創新的線上強化學習演演算法,用於訓練能夠在野外環境中控制設備的智慧代理。它透過自主價值評估模型(VLM)來解決開放式的、現實世界中的Android任務。DigiRL的主要優點包括能夠利用現有的非最優離線資料集,並透過離線到線上的強化學習來鼓勵代理從自身的嘗試和錯誤中學習。該模型使用指令級價值函式來隱式構建自動課程,優先考慮對代理最有價值的任務,並透過步進級價值函式挑選出在軌跡中對目標有貢獻的有利動作。
需求人群:
- DigiRL的目標受眾主要是人工智慧和機器學習領網網域的研究人員與開發者,特別是那些專注於強化學習、自主智慧代理以及設備控制自動化的專業人士。他們可以利用DigiRL來開發能夠適應不斷變化環境的智慧系統,提高自動化任務的效率和準確性。
使用場景示例:
-
在搜尋好的義大利餐廳時,DigiRL能夠自動完成搜尋任務。
-
在新蛋網上搜尋Alienware Aurora時,DigiRL能夠自動導覽至產品頁面並執行搜尋。
-
在訓練過程中,DigiRL能夠透過自主資料更新維持穩定的效能,即使在網站變化時也能保持高效。
產品特色:
- 使用自主VLM評估器解決開放式Android任務
- 透過離線強化學習最大化現有資料集的利用
- 採用離線到線上的強化學習鼓勵代理自我學習
- 使用指令級價值函式構建自動課程
- 利用步進級價值函式挑選有利動作
- 透過自主收集的rollout訓練,減少從錯誤中恢復的失敗
- 與現有的行為克隆方法相比,具有更低的樣本複雜度和更高的學習效率
使用教學:
1. 訪問DigiRL的官方網站以獲取更多資訊。
2. 閱讀DigiRL的論文和程式碼,瞭解其演演算法和實作細節。
3. 下載並安裝必要的軟體環境,以執行DigiRL模型。
4. 根據DigiRL的指導文檔設定實驗環境,包括資料集和引數配置。
5. 執行DigiRL模型,觀察其在不同任務上的表現。
6. 根據實驗結果調整模型引數,最佳化DigiRL的效能。
7. 將DigiRL應用於實際的設備控制任務,實作自動化操作。