YOLOv8:YOLOv8目標檢測跟蹤模型
YOLOv8是YOLO系列目標檢測模型的最新版本,能夠在影象或影片中準確快速地識別和定位多個對象,並實時跟蹤它們的移動。相比之前版本,YOLOv8在檢測速度和精確度上都有很大提升,同時支援多種額外的計算機視覺任務,如例項分割、姿態估計等。YOLOv8可透過多種格式部署在不同硬體平臺上,提供一站式的端到端目標檢測解決方案。
YOLOv8是YOLO系列目標檢測模型的最新版本,能夠在影象或影片中準確快速地識別和定位多個對象,並實時跟蹤它們的移動。相比之前版本,YOLOv8在檢測速度和精確度上都有很大提升,同時支援多種額外的計算機視覺任務,如例項分割、姿態估計等。YOLOv8可透過多種格式部署在不同硬體平臺上,提供一站式的端到端目標檢測解決方案。

VisFusion是一個利用影片資料進行線上3D場景重建的技術,它能夠實時地從影片中提取和重建出三維環境。這項技術結合了計算機視覺和深度學習,為使用者提供了一個強大的工具,用於建立精確的三維模型。
AnimateLCM-SVD-xt是一種新的影象到影片生成模型,可以在很少的步驟內生成高質量、連貫性好的影片。該模型透過一致性知識蒸餾和立體匹配學習技術,使生成影片更加平穩連貫,同時大大減少了計算量。關鍵特點包括:1) 4-8步內生成25幀576×1024解析度影片;2) 比普通影片diffusion模型降低12.5倍計算量;3) 生成影片質量好,無需額外分類器引導。
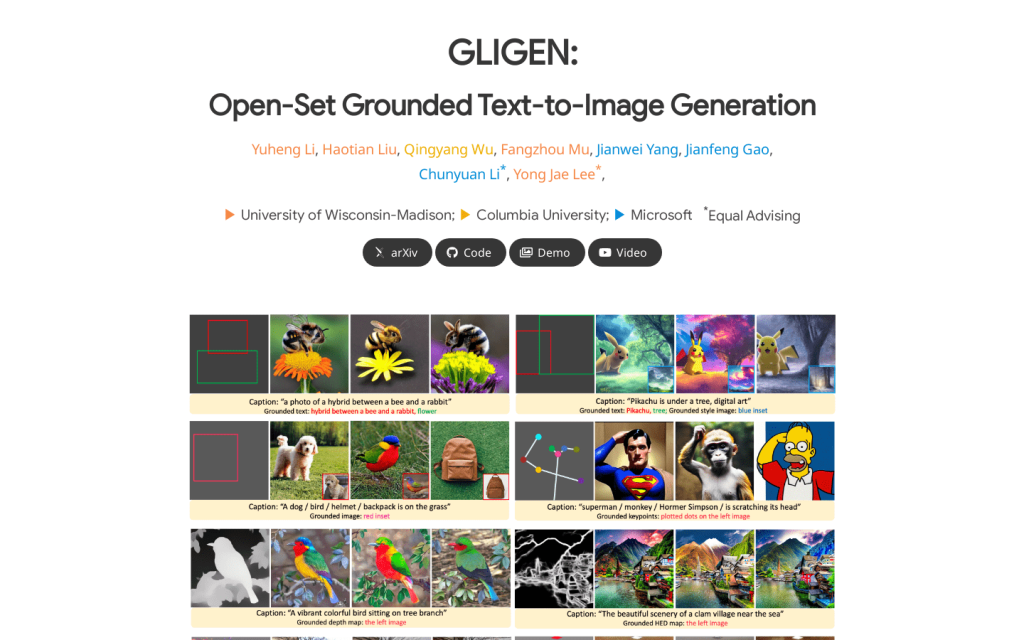
GLIGEN是一個開放式的基於文字提示的影象生成模型,它可以基於文字描述和邊界框等限定條件生成影象。該模型透過凍結預訓練好的文字到影象Diffusion模型的引數,並在其中插入新的資料來實現。這種模組化設計可以高效地進行訓練,並具有很強的推理靈活性。GLIGEN可以支援開放世界的有條件影象生成,對新出現的概念和佈局也具有很強的泛化能力。
Vision Arena是一個由Hugging Face建立的開源平臺,用於測試和比較不同的計算機視覺模型效果。它提供了一個友好的介面,允許使用者上傳圖片並透過不同模型處理,從而直觀地對比結果質量。平臺預裝了主流的影象分類、對象檢測、語義分割等模型,也支援自定義模型。關鍵優勢是開源免費,使用簡單,支援多模型並行測試,有利於模型效果評估和選擇。適用於計算機視覺研發人員、演演算法工程師等角色,可以加速計算機視覺模型的實驗和調優。
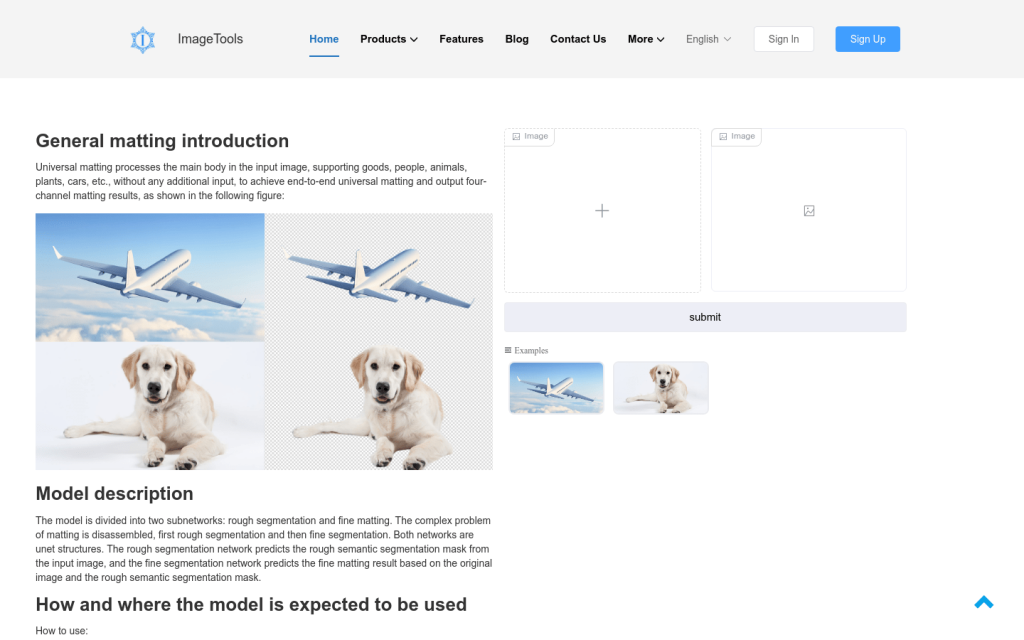
ImageTools是一款通用摳圖工具,透過先進的計算機視覺演演算法,精確自動地從照片中移除背景,突顯主體。適用於影象編輯、廣告設計、電商等場景,提供使用者在各種情境中展示影象主體的靈活性和創造空間。

LiveFood是一個包含超過5100個美食影片的資料集,影片包括食材、烹飪、呈現和食用四個領域,所有影片均由專業工人精細註釋,並採用嚴格的雙重檢查機制進一步保證註釋質量。我們還提出了全域性原型編碼(GPE)模型來處理這個增量學習問題,與傳統技術相比獲得了競爭性的效能。
HeyGen 5.0是一款下一代AI影片平臺。它擁有數字化虛擬人物、語音轉文字和影片翻譯等技術,任何人都可以輕鬆製作出工作室級別的高質量影片。該平臺的主要特點包括:先進的AI工作室,為使用者提供更多音訊、元素、動畫等靈活控制,輕鬆建立令人難忘的影片內容。大規模批次化製作個性化影片,適用於獲取銷售線索、歡迎新員工入職、面向學生等各種場合。站在科技前沿,為團隊每個成員賦能視覺講述能力。HeyGen 5.0致力於讓每個人都能建立吸引人的影片內容,成為視覺講述大師。
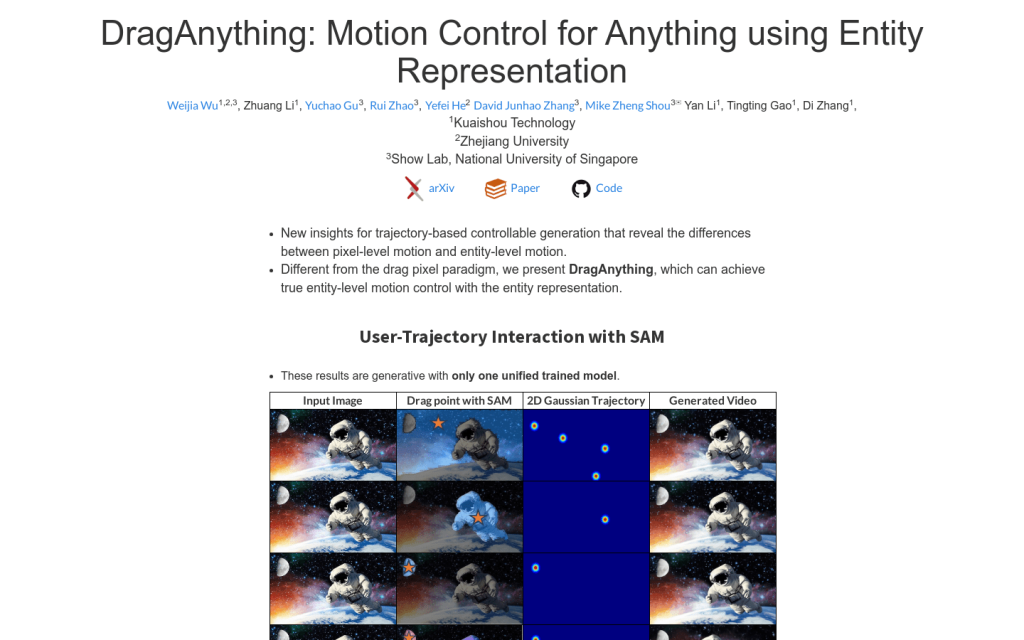
DragAnything是一款利用實體表示實現任意物體運動控制的產品。與拖動畫素的傳統方式不同,DragAnything可以實現真正的實體級運動控制。它可以實現使用者軌跡互動,並具有SAM功能。該產品可以精確控制物體的運動,生成高質量影片,使用者只需在互動過程中繪製一條軌跡。DragAnything可實現對前景、背景和相機等不同元素的多樣化運動控制。定位於設計領域,適用於需要對影片中物體進行精細控制的場景。產品定價未公開。
OptimizerAI專注於使用人工智慧技術生成各種聲音效果,旨在為遊戲、影片、短片、廣告等多媒體內容增添活力。該平臺提供了高質量的音訊生成服務,並計劃推出文字到聲音效果生成功能。