TripoSR:從單張圖片快速生成3D對象
TripoSR是由Stability AI與Tripo AI合作開發的3D對象重建模型,能夠從單張圖片在不到一秒鐘的時間內生成高質量的3D模型。該模型在低推理預算下執行,無需GPU,適用於廣泛的使用者和應用場景。模型權重和原始碼已在MIT許可下發布,允許商業化、個人和研究使用。
TripoSR是由Stability AI與Tripo AI合作開發的3D對象重建模型,能夠從單張圖片在不到一秒鐘的時間內生成高質量的3D模型。該模型在低推理預算下執行,無需GPU,適用於廣泛的使用者和應用場景。模型權重和原始碼已在MIT許可下發布,允許商業化、個人和研究使用。
DUSt3R是一種新穎的密集和無約束立體3D重建方法,適用於任意影象集合。它不需要事先瞭解相機校準或視點姿態資訊,透過將成對重建問題視為點圖的迴歸,放寬了傳統投影相機模型的嚴格約束。DUSt3R提供了一種統一的單目和雙目重建方法,並在多影象情況下提出了一種簡單有效的全域性對齊策略。基於標準的Transformer編碼器和解碼器構建網路架構,利用強大的預訓練模型。DUSt3R直接提供場景的3D模型和深度資訊,並且可以從中恢復畫素匹配、相對和絕對相機資訊。
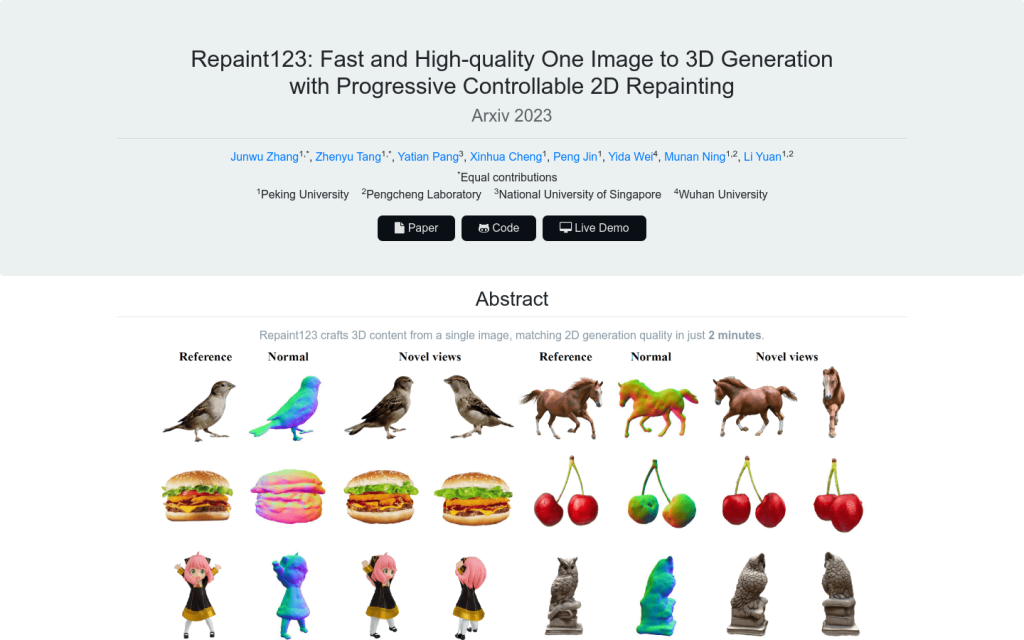
Repaint123可以在2分鐘內從一張圖片生成高質量、多視角一致的3D內容。它結合2D散射模型強大的影象生成能力和漸進重繪策略的紋理對齊能力,生成高質量、視角一致的多視角影象,並透過可視性感知的自適應重繪強度提升重繪過程中的影象質量。生成的高質量、多視角一致影象使得簡單的均方誤差損失函式就能實現快速的3D內容生成。

ReconFusion是一種3D重建方法,利用擴散先驗在只有少量照片的情況下重建真實世界場景。它結合Neural Radiance Fields(NeRFs)和擴散先驗,能夠在新的攝像機位置超出輸入影象集合的情況下,合成逼真的幾何和紋理。該方法透過在少量檢視和多檢視資料集上訓練擴散先驗,能夠在不受約束的區域合成逼真的幾何和紋理,同時保留觀察區域的外觀。ReconFusion在各種真實世界資料集上進行了廣泛評估,包括前向和360度場景,展示出明顯的效能改進。
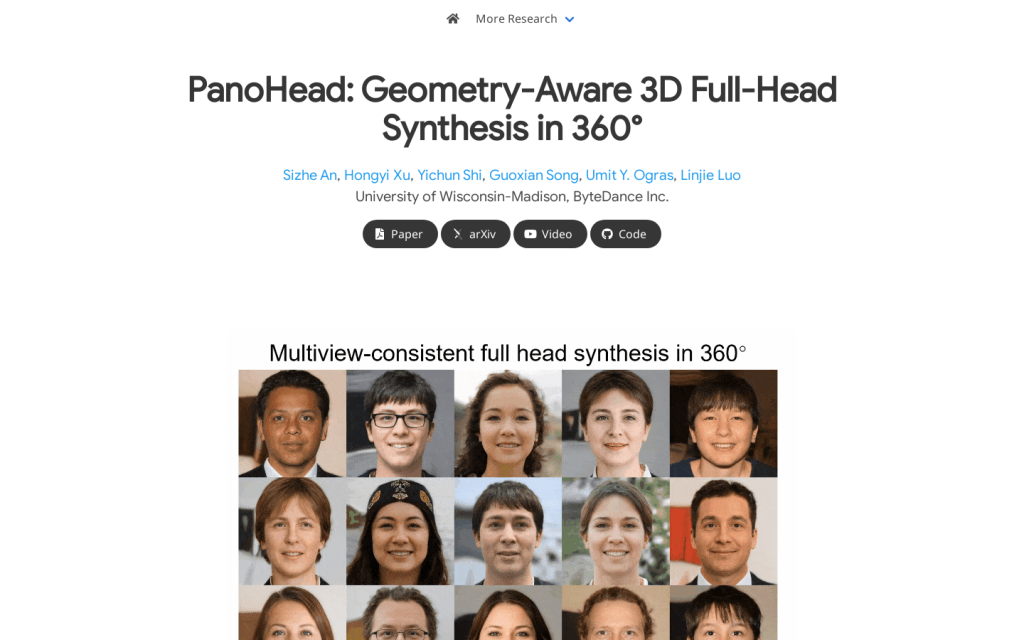
PanoHead是一個360°幾何感知3D全頭合成方法,能夠僅依靠野外非結構化影象進行訓練,實現高質量檢視一致的360°全頭部影象合成,具有不同的外觀和詳細的幾何形狀。

Neuralangelo是NVIDIA研究推出的一款利用神經網路進行3D重建的人工智慧模型,可以將2D影片片段轉換為詳細的3D結構,生成逼真的虛擬建築、雕塑等物體。它能夠準確地提取複雜材料的紋理,包括屋頂瓦片、玻璃窗格和光滑的大理石。創意專業人員可以將這些3D對象匯入設計應用程式,進一步進行編輯,用於藝術、影片遊戲開發、機器人技術和工業數字雙胞胎等領域。Neuralangelo的3D重建能力將對創作者產生巨大的幫助,幫助他們在數字世界中重新建立真實世界。該工具最終將使開發人員能夠將詳細的對象(無論是小雕塑還是巨大的建築物)匯入到虛擬環境中,用於影片遊戲或工業數字雙胞胎等應用。

Gaussian SLAM能夠從RGBD資料流重建可渲染的3D場景。它是第一個能夠以照片級真實感重建現實世界場景的神經RGBD SLAM方法。透過利用3D高斯作為場景表示的主要單元,我們克服了以往方法的侷限性。我們觀察到傳統的3D高斯在單目設定下很難使用:它們無法編碼準確的幾何資訊,並且很難透過單檢視順序監督進行最佳化。透過擴充套件傳統的3D高斯來編碼幾何資訊,並設計一種新穎的場景表示以及增長和最佳化它的方法,我們提出了一種能夠重建和渲染現實世界資料集的SLAM系統,而且不會犧牲速度和效率。高斯SLAM能夠重建和以照片級真實感渲染現實世界場景。我們在常見的合成和真實世界資料集上對我們的方法進行了評估,並將其與其他最先進的SLAM方法進行了比較。最後,我們證明了我們得到的最終3D場景表示可以透過高效的高斯飛濺渲染實時渲染。
ComfyUI-3D-Pack是一個強大的3D處理外掛集合,它為ComfyUI提供了處理3D模型(網格、紋理等)的能力,整合了各種前沿3D重建和渲染演演算法,如3D高斯取樣、NeRF不同iable渲染等,可以實現單視角影象快速重建3D高斯模型,並可轉換為三角網格模型,同時還提供了互動式3D視覺化介面。

VisFusion是一個利用影片資料進行線上3D場景重建的技術,它能夠實時地從影片中提取和重建出三維環境。這項技術結合了計算機視覺和深度學習,為使用者提供了一個強大的工具,用於建立精確的三維模型。

GRM是一種大規模的重建模型,能夠在0.1秒內從稀疏檢視影象中恢復3D資產,並且在8秒內實現生成。它是一種前饋的基於Transformer的模型,能夠高效地融合多檢視資訊將輸入畫素轉換為畫素對齊的高斯分佈,這些高斯分佈可以反投影成為表示場景的密集3D高斯分佈集合。我們的Transformer架構和使用3D高斯分佈的方式解鎖了一種可擴充套件、高效的重建框架。大量實驗結果證明了我們的方法在重建質量和效率方面優於其他替代方案。我們還展示了GRM在生成任務(如文字到3D和影象到3D)中的潛力,透過與現有的多檢視擴散模型相結合。