Inbox Zero:快速達到郵箱零收件箱的虛擬助手
Inbox Zero是一個開源電子郵件應用,旨在幫助使用者快速清理收件箱。它提供新聞通訊管理、AI自動化和電子郵件分析功能,幫助使用者節省時間,提高工作效率。
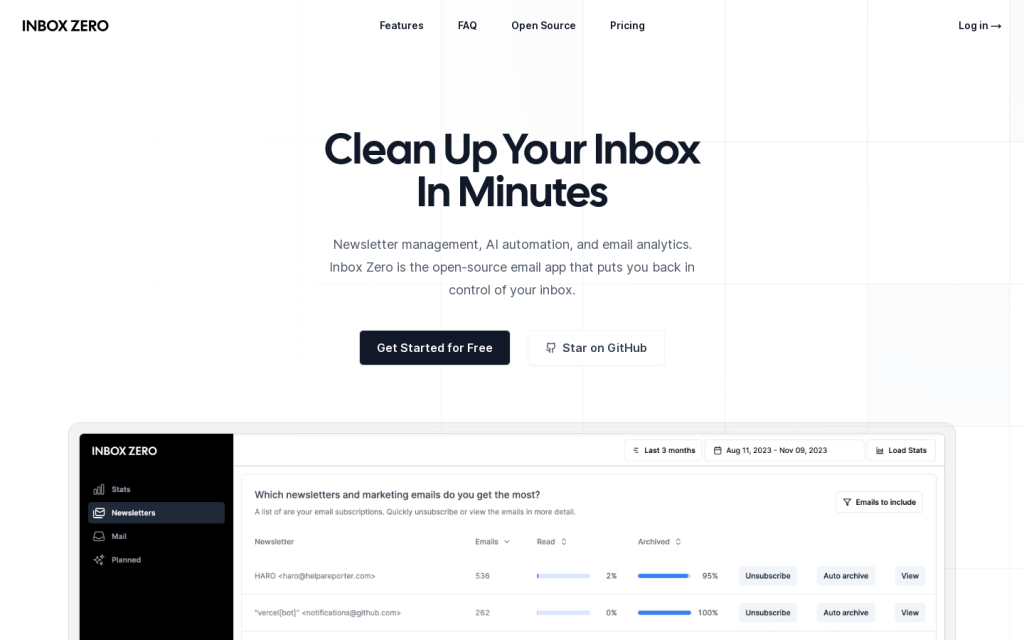
Inbox Zero是一個開源電子郵件應用,旨在幫助使用者快速清理收件箱。它提供新聞通訊管理、AI自動化和電子郵件分析功能,幫助使用者節省時間,提高工作效率。

Yi是一款全球領先的預訓練模型,在多項評測中取得了SOTA國際最佳效能指標表現。它具有輕巧的模型尺寸,超越了大尺寸開源模型,更加友好於開發者社群。零一萬物適合個人及研究用途,並且已具備大模型湧現能力,適用於多元場景,滿足開源社區的剛性需求。Yi開源模型對學術研究完全開放,並且同步開放免費商用申請。
Stability AI 生成模型是一個開源的生成模型庫,提供了各種生成模型的訓練、推理和應用功能。該庫支援各種生成模型的訓練,包括基於 PyTorch Lightning 的訓練,提供了豐富的配置選項和模組化的設計。使用者可以使用該庫進行生成模型的訓練,並透過提供的模型進行推理和應用。該庫還提供了示例訓練配置和資料處理的功能,方便使用者進行快速上手和定製。
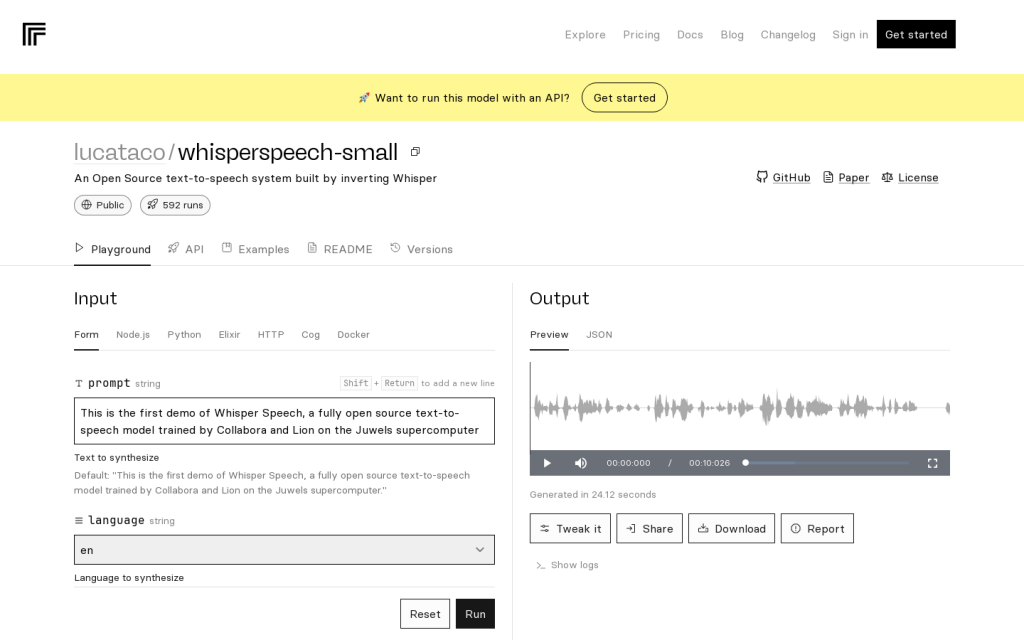
Whisper Speech是一款完全開源的文字轉語音模型,由Collabora和Lion在Juwels超級計算機上訓練。它支援多種語言和多種形式的輸入,包括Node.js、Python、Elixir、HTTP、Cog和Docker。該模型的優勢在於高效的語音合成和靈活的部署方式。定價方面,Whisper Speech完全免費。它定位於為開發者和研究人員提供一個強大的、可定製的文字轉語音解決方案。

Code Llama 70B是一個大型開原始碼生成語言模型,可以從自然語言提示或現有程式碼片段生成多種程式設計語言的程式碼。它基於175億引數的通用語言模型Llama 2,經過專門針對程式碼生成任務的微調,可以高效準確地生成Python、C++、Java等語言的程式碼。Code Llama 70B在人工評估基準測試中取得了67.8的高分,效能超過了以往的開源模型,可與專利模型媲美。它強大的程式碼生成能力可以提升程式設計效率,降低編碼門檻,啟發更多創新應用。
Gemma是Google推出的一系列開源的輕量級語言模型系列。它結合了全面的安全措施,在尺寸上實現了優異的效能,甚至超過了一些較大的開放模型。可以無縫相容各種框架。提供快速入門指南、基準測試、模型獲取等,幫助開發者負責任地開發AI應用。
OLMo是一個開源的語言模型和訓練框架,由AI2研究院釋出。它提供了完整的訓練資料、程式碼、模型引數、評估程式碼等資源,使研究人員能夠訓練並實驗大規模語言模型。OLMo的優勢在於真正開放,使用者可以訪問從資料到模型的完整資訊,輔以豐富的檔案,便於研究人員進行開放式研究和協作。該框架降低了語言模型研究的門檻,使更多人參與進來推動語言模型技術進步。
Lepton是一個開源的自然語言處理平臺,提供語言理解、生成和推理能力。它採用Transformer模型架構,能夠進行多輪對話、問答、文字生成等任務。Lepton具有高效、可擴充套件的特點,可以在多個領域部署使用。

Llama Family是一個開源平臺,致力於構建開放的Llama模型生態,包含多種大模型和程式碼模型。具有豐富的功能和優勢,提供各種算力獲取和模型訓練合作方式。價格根據合作方式而定,包括免費和付費選項。主要功能包括模型訓練、算力獲取、開源生態共建等。適用於各種技術愛好者和開發者。

MediaTek Research釋出了名為MR Breeze-7B的新開源大型語言模型,擁有70億引數,擅長處理中英文。相比先前的BLOOM-3B,MR Breeze-7B吸收了20倍的知識,使其能夠精準處理傳統中文語言的文化和語言細微差別。最佳化後,MR Breeze-7B在處理速度上勝過其他模型,為使用者帶來更流暢的體驗。定價免費。