PodBravo:自動化生成獨特內容
PodBravo是一個自動化的內容生成工具,可以透過人工智慧為您的播客創作轉錄、節目摘要、時間戳、標題、部落格文章、社交媒體帖子、影片片段等內容,提升您的播客的受眾範圍。不需要額外的工作,只需點選一次即可生成多種內容。價格方案靈活,適用於任何規模的播客製作。
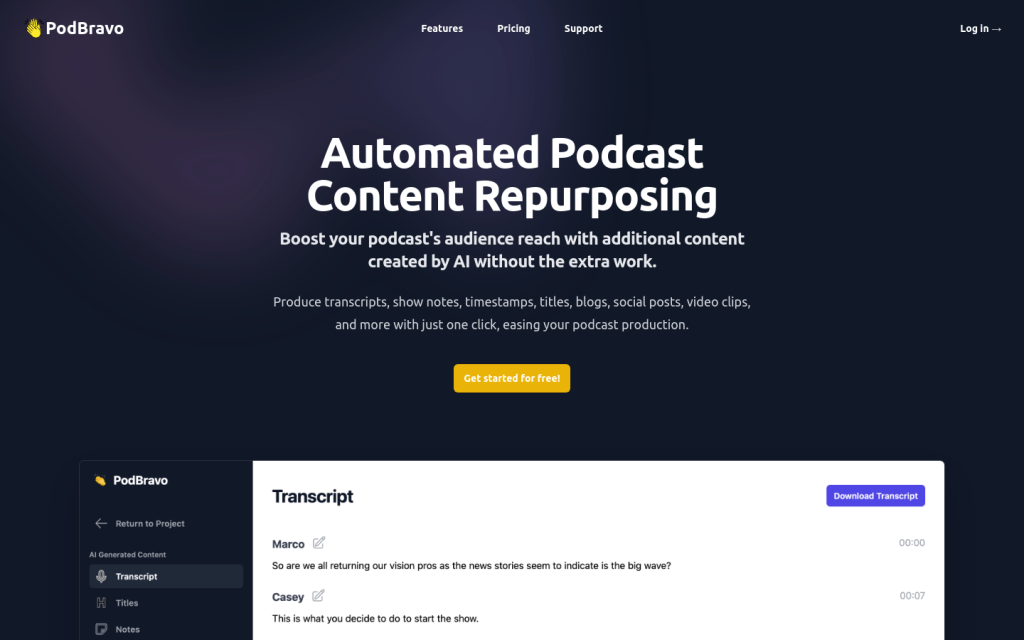
PodBravo是一個自動化的內容生成工具,可以透過人工智慧為您的播客創作轉錄、節目摘要、時間戳、標題、部落格文章、社交媒體帖子、影片片段等內容,提升您的播客的受眾範圍。不需要額外的工作,只需點選一次即可生成多種內容。價格方案靈活,適用於任何規模的播客製作。

Large World Models是一個利用RingAttention技術訓練的神經網路,專注於處理長影片和語言序列,以理解人類知識和多模態世界。它透過大規模資料集訓練,實現了前所未有的上下文大小,並開源了一系列70億引數的模型,能夠處理超過100萬標記的文字和影片。
gemma.cpp是谷歌為Gemma模型開發的輕量級、獨立的C++推理引擎。它專注於為Gemma 2B和7B模型提供簡潔、直接的實現,旨在支援研究和實驗用例,易於嵌入其他專案且具有高度的可修改性。gemma.cpp利用Google Highway庫,最佳化了CPU推理效能。
Open-Sora-Plan是一個開源專案,旨在復現OpenAI的Sora(T2V模型),並構建關於Video-VQVAE(VideoGPT)+ DiT的知識。專案由北京大學-兔展AIGC聯合實驗室發起,目前資源有限,希望開源社區能夠貢獻力量。專案提供了訓練程式碼,並歡迎Pull Request。
DataDreamer是一個強大的開源Python庫,用於提示、生成合成資料和訓練工作流。它旨在簡單易用,極其高效,且具有研究級質量。DataDreamer支援建立提示工作流、生成合成資料集、對齊模型、微調模型、指令調優模型和模型蒸餾。它具有簡單、研究級、高效、可復現的特點,並簡化了資料集和模型的共享。
Intel NPU Acceleration Library是英特爾為神經處理單元(NPU)開發的加速庫,旨在提高深度學習和機器學習應用的效能。該庫提供了針對英特爾硬體最佳化的演演算法和工具,支援多種深度學習框架,能夠顯著提升模型的推理速度和效率。
llama_parse是LLAMA專案的一部分,用於解析和處理相關資料。LLAMA是一個用於機器學習模型的庫,專注於提供易於使用的介面和高效的資料處理能力。
gpt-prompt-engineer是一個專注於GPT模型提示工程的資源庫,旨在提供關於如何有效地與GPT模型互動、如何構造提示以引導模型生成期望輸出的技巧和策略。
華為開源自研AI框架MindSpore。自動微分、並行加持,一次訓練,可多場景部署。支援端邊雲全場景的深度學習訓練推理框架,主要應用於計算機視覺、自然語言處理等AI領域,面向資料科學家、演演算法工程師等人群。主要具備基於原始碼轉換的通用自動微分、自動實現分散式並行訓練、資料處理、以及圖執行引擎等功能特性。藉助自動微分,輕鬆訓練神經網路。框架開源,華為培育AI開發生態。