MakeML:無程式碼搭建目標檢測神經網路
MakeML是一個無需編寫任何程式碼就可以搭建影象目標檢測神經網路的開發工具。它提供了一個簡單易用的圖形介面,使用者只需上傳訓練集圖片,繪製bounding box,設定引數,就可以訓練出一個高效的目標檢測模型,並匯出成CoreML格式在iOS App中使用。MakeML解決了神經網路開發門檻高的痛點,不需要任何機器學習或程式設計知識,就可以獲得強大的深度學習能力。
MakeML是一個無需編寫任何程式碼就可以搭建影象目標檢測神經網路的開發工具。它提供了一個簡單易用的圖形介面,使用者只需上傳訓練集圖片,繪製bounding box,設定引數,就可以訓練出一個高效的目標檢測模型,並匯出成CoreML格式在iOS App中使用。MakeML解決了神經網路開發門檻高的痛點,不需要任何機器學習或程式設計知識,就可以獲得強大的深度學習能力。
The Microsoft Cognitive Toolkit(CNTK)是一個開源的商業級分散式深度學習工具。它透過有向圖描述神經網路的計算步驟,支援常見的模型型別,並實現了自動微分和平行計算。CNTK支援64位Linux和Windows作業系統,可以作為Python、C或C++程式的庫使用,也可以透過其自身的模型描述語言BrainScript作為獨立的機器學習工具使用。
清圖是一款基於深度學習技術的影象處理工具,能夠將模糊圖片快速轉換為高畫質圖。它採用先進的演演算法對圖片進行重建,使得圖片的細節更加清晰、銳利。清圖還提供摳圖、證件照處理、黑白圖片上色、圖片超級壓縮、修改圖片 DPI 等功能。它適用於個人使用者、攝影師、設計師等多個場景。

VideoCrafter2是一個影片生成AI模型,能夠根據文字描述生成高質量、流暢的影片。它透過克服資料侷限,實現了高質量影片生成的目標。該模型可以生成照片級質量的影片,支援精細的運動控制和概念組合。使用者只需要提供文字描述,VideoCrafter2就可以自動生成劇本級別的影片作品,可用於影片創作、動畫製作等領域。

AnimateLCM是一個使用深度學習生成動畫影片的模型。它可以僅使用極少的取樣步驟就生成高保真的動畫影片。與直接在原始影片資料集上進行一致性學習不同,AnimateLCM採用瞭解耦的一致性學習策略,將影象生成先驗知識和運動生成先驗知識的萃取進行解耦,從而提高了訓練效率並增強了生成的視覺質量。此外,AnimateLCM還可以與Stable Diffusion社區的外掛模組配合使用,實現各種可控生成功能。AnimateLCM已經在基於影象的影片生成和基於佈局的影片生成中驗證了其效能。
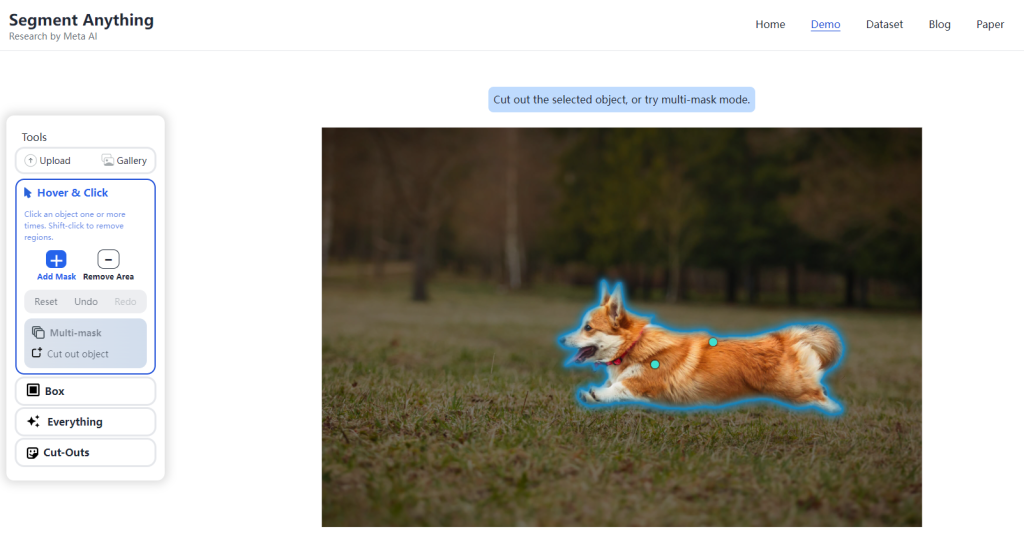
SAM是一個可提示的分割系統,能夠對不熟悉的對象和影象進行零樣本泛化,無需額外訓練。它使用各種輸入提示,可以進行廣泛的分割任務,無需額外訓練。它的可提示設計可以與其他系統靈活整合。它在1100萬張影象上訓練,擁有10億個分割掩模。它的高效模組化設計使其可以在幾毫秒內進行推理。Segment Anything Model (SAM),該模型能夠根據文字指令等方式實現影象分割,而且萬物皆可識別和一鍵摳圖,上傳圖片點選物體即可識別。
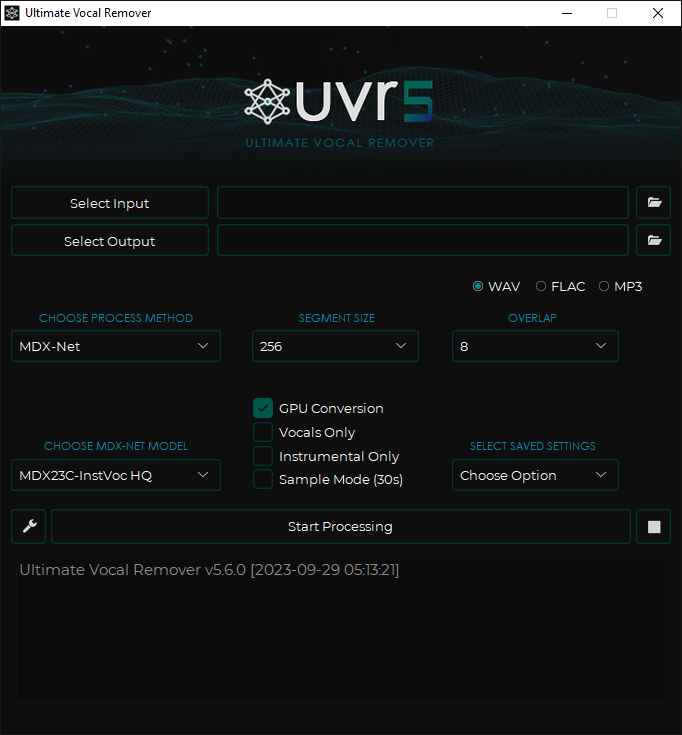
終極人聲去除GUI是一款使用深度神經網路技術的人聲去除工具。其核心開發者訓練了所有提供的模型,除了Demucs v3和v4 4聲道模型。該應用使用先進的源分離模型從音訊檔案中去除人聲。無需額外的先決條件即可有效執行。適用於Windows 10及以上版本。
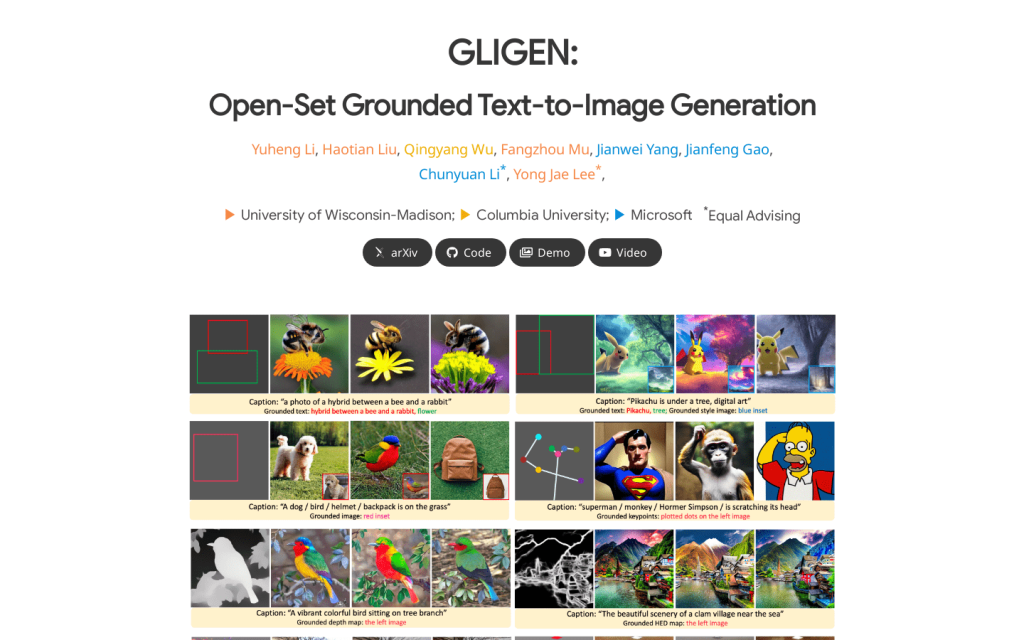
GLIGEN是一個開放式的基於文字提示的影象生成模型,它可以基於文字描述和邊界框等限定條件生成影象。該模型透過凍結預訓練好的文字到影象Diffusion模型的引數,並在其中插入新的資料來實現。這種模組化設計可以高效地進行訓練,並具有很強的推理靈活性。GLIGEN可以支援開放世界的有條件影象生成,對新出現的概念和佈局也具有很強的泛化能力。
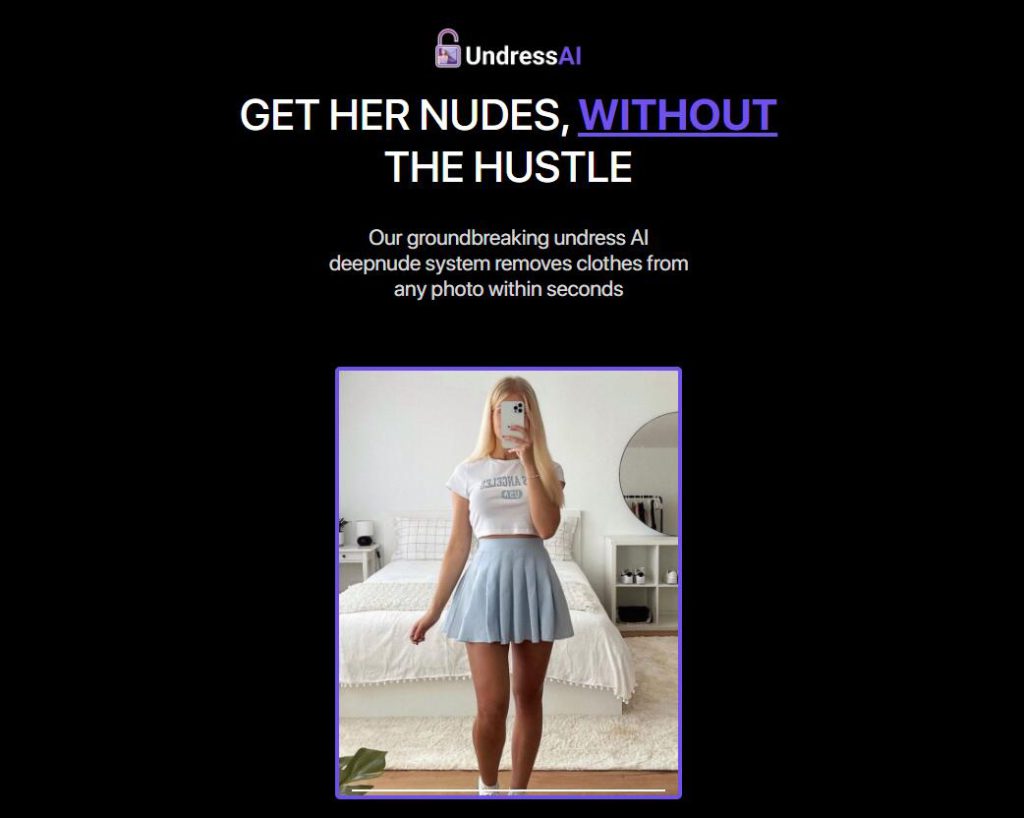
Undress AI是一款使用深度學習技術的產品,可以在幾秒鐘內從任何照片中去除衣物。我們使用最先進的SHA512加密技術,安全儲存所有解除衣物的照片。使用Undress AI,您可以成為擁有她私密照片的獨家人士。
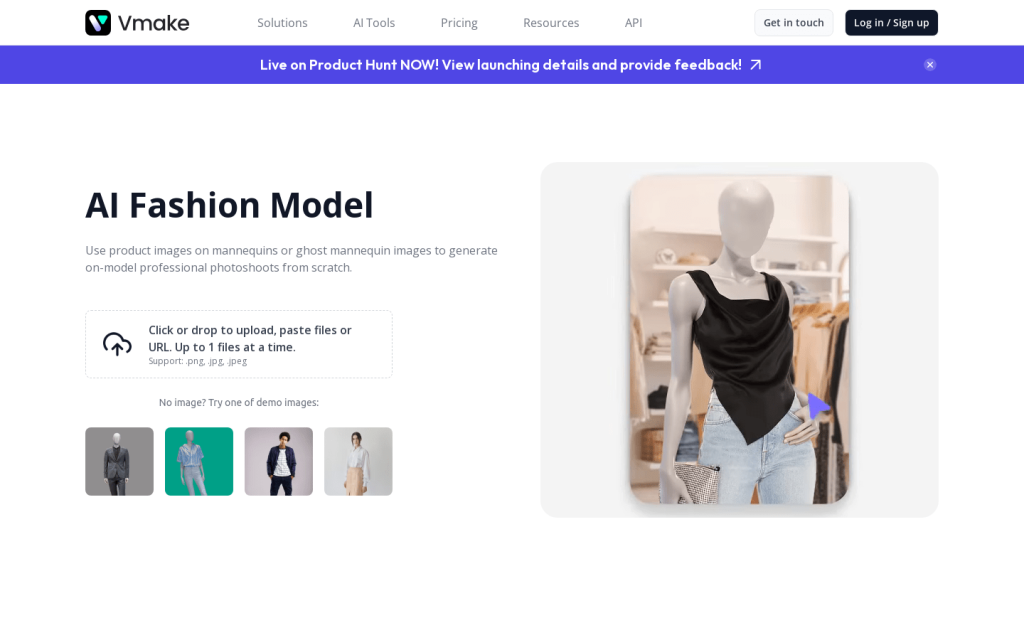
AI Fashion Model Studio可以為您的服裝品牌生成專業的模特照片。您可以上傳自己的服裝設計,選擇不同膚色、體型和髮色的虛擬模特,一鍵生成高質量的模特照片。該產品提供成本低廉的模特替代方案,同時保證視覺營銷效果,有助於提高電商轉化率。