SketchDeco:將手繪草圖變為現實色彩影象
SketchDeco是一個創新的線上工具,它能夠將黑白草圖、遮罩和色彩調色盤轉化為逼真的彩色影象,無需使用者定義文本提示。這項技術結合了ControlNet和分階段生成的方法,使用Stable Diffusion v1.5和BLIP-2文本提示,提供了忠實的影象生成和使用者導向的色彩化。

SketchDeco是一個創新的線上工具,它能夠將黑白草圖、遮罩和色彩調色盤轉化為逼真的彩色影象,無需使用者定義文本提示。這項技術結合了ControlNet和分階段生成的方法,使用Stable Diffusion v1.5和BLIP-2文本提示,提供了忠實的影象生成和使用者導向的色彩化。
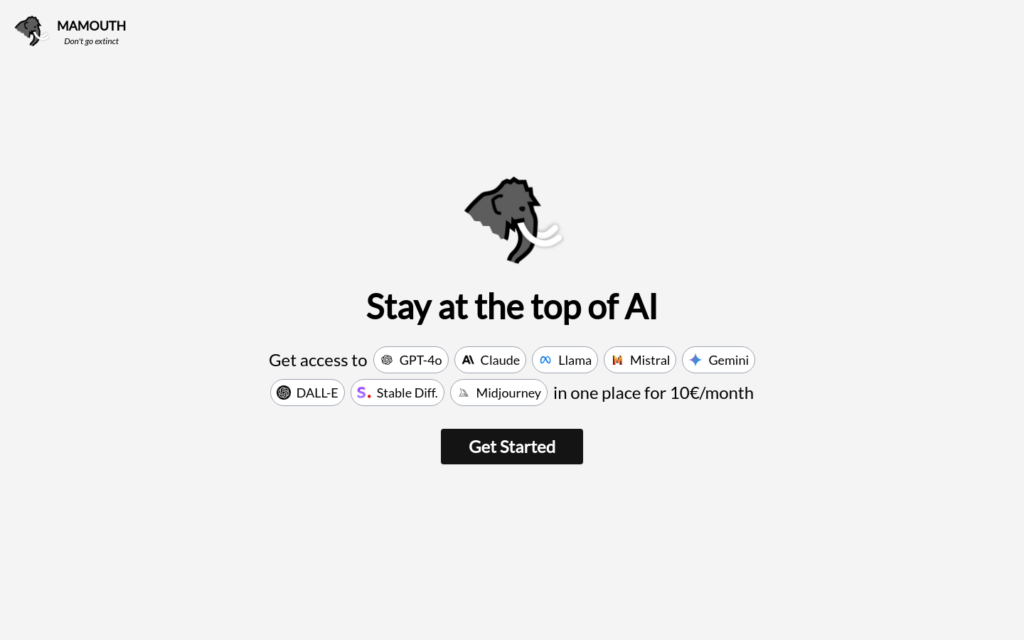
Mamouth是一個整合了多種先進AI模型和影象生成服務的平臺,旨在幫助使用者保持在人工智慧技術的前沿。平臺提供包括GPT-4o、Claude、Llama、Mistral、Gemini等在內的AI語言模型,以及Dall-E、Midjourney和Stable Diffusion等影象生成工具。
ComfyUI_omost是一個基於ComfyUI框架實作的Omost模型,它允許使用者與大型語言模型(LLM)進行互動,以獲取類似JSON的結構化佈局提示。該模型目前處於開發階段,其節點結構可能會有變化。它透過LLM Chat和Region Condition兩個部分,將JSON條件轉換為ComfyUI的區網域格式,用於影象生成和編輯。

HyperDreamBooth是由Google Research開發的一種超網路,用於快速個性化文本到影象模型。它透過從單張人臉影象生成一組小型的個性化權重,結合快速微調,能夠在多種上下文和風格中生成具有高主題細節的人臉影象,同時保持模型對多樣化風格和語義修改的關鍵知識。
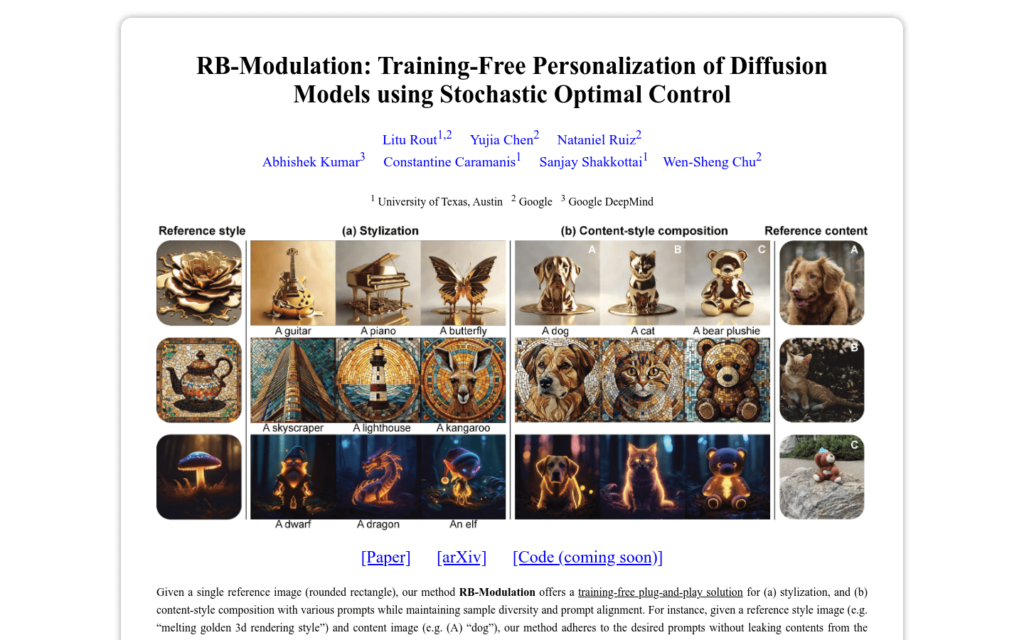
RB-Modulation是谷歌釋出的一種基於隨機最優控制的新型訓練免費個性化擴散模型解決方案。它透過終端成本編碼所需屬性,實作風格和內容的精確提取與控制,無需額外訓練,即可生成與參考影象風格一致且遵循給定文本提示的影象。該技術在無需訓練的情況下,透過新穎的注意力特徵聚合(AFA)模組。
Omost是一個旨在將大型語言模型(LLM)的編碼能力轉化為影象生成(更準確地說是影象組合)能力的專案。它提供了基於Llama3和Phi3變體的預訓練LLM模型,這些模型能夠編寫程式碼以使用Omost的虛擬Canvas代理來組合影象視覺內容。Canvas可以由特定的影象生成器實作來實際生成影象。
Era3D是一個開源的高解析度多視角擴散模型,它透過高效的行注意力機制來生成高質量的影象。該模型能夠生成多視角的顏色和法線影象,支援自訂引數以獲得最佳結果。Era3D在影象生成領網域具有重要性。
ToonCrafter是一個開源的研究專案,專注於使用預訓練的影象到影片擴散先驗來插值兩張卡通影象。該專案旨在積極影響AI驅動的影片生成領網域,為使用者提供創造影片的自由,但要求使用者遵守當地法律並負責任地使用。
SDXL Flash是由SD社群與Project Fluently合作推出的文本到影象生成模型。它在保持生成影象質量的同時,提供了比LCM、Turbo、Lightning和Hyper更快的處理速度。該模型基於Stable Diffusion XL技術,透過最佳化步驟和CFG(Guidance)引數,實作了影象生成的高效率和高質量。

AnyDoor AI是一款突破性的影象生成工具,其設計理念基於擴散模型。它可以無縫地將目標物體嵌入到使用者指定的新場景位置。AnyDoor從本質上重新定義了影象操作,承諾在日常互動中提供多種更人性化的應用。