DIG-In:評估影象生成模型在不同地理區網域的質量、多樣性和一致性
DIG-In是一個用於評估文本到影象生成模型在不同地理區網域中質量、多樣性和一致性差異的庫。它使用GeoDE和DollarStreet作為參考資料集,透過計算生成影象的相關特徵和精度、覆蓋度指標,以及使用CLIPScore指標來衡量模型的表現。
DIG-In是一個用於評估文本到影象生成模型在不同地理區網域中質量、多樣性和一致性差異的庫。它使用GeoDE和DollarStreet作為參考資料集,透過計算生成影象的相關特徵和精度、覆蓋度指標,以及使用CLIPScore指標來衡量模型的表現。
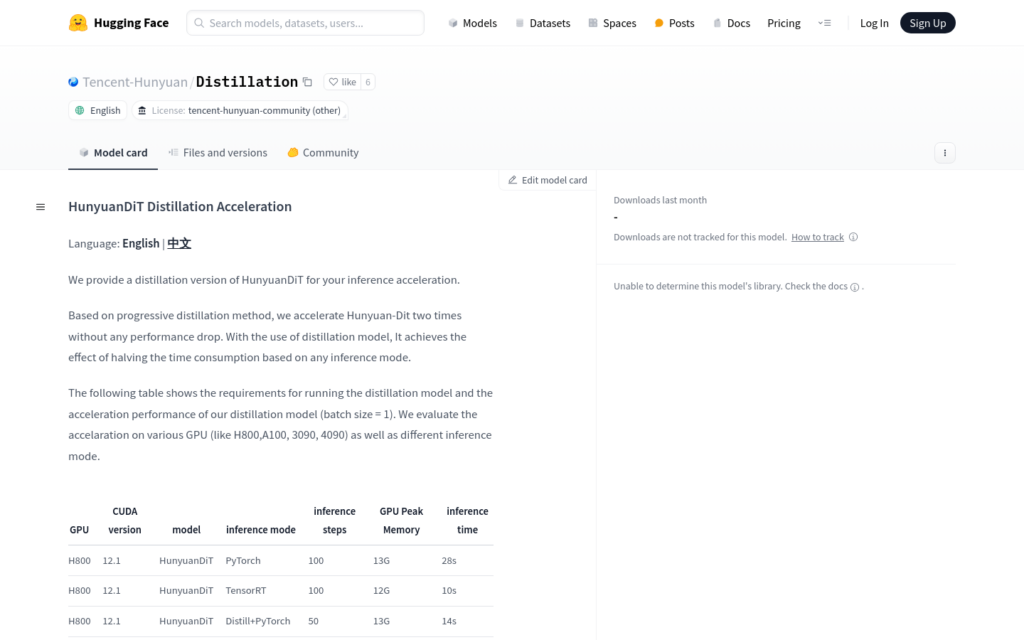
HunyuanDiT Distillation Acceleration 是騰訊 Hunyuan 團隊基於 HunyuanDiT 模型開發的蒸餾加速版本。透過漸進式蒸餾方法,在不降低效能的情況下,實作了推理速度的兩倍提升。該模型支援多種GPU和推理模式,能夠顯著減少時間消耗,提高影象生成效率。
InstantX是一個專注於AI內容生成的獨立研究組織,致力於文本到影象的生成技術。其研究專案包括風格保持的文本到影象生成(InstantStyle)和零樣本身份保持生成(InstantID)。該組織透過GitHub社群進行專案更新和交流,推動AI在影象生成領網域的應用和發展。
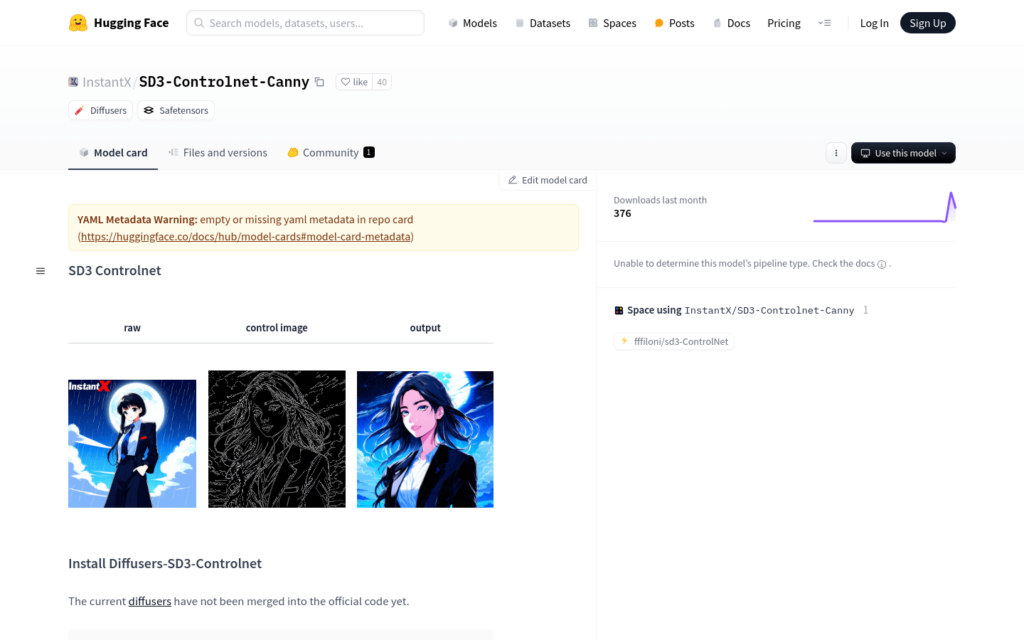
SD3-Controlnet-Canny 是一種基於深度學習的影象生成模型,它能夠根據使用者提供的文本提示生成具有特定風格的影象。該模型利用控制網路技術,可以更精確地控制生成影象的細節和風格,從而提高影象生成的質量和多樣性。
EMMA是一個基於最前沿的文本到影象擴散模型ELLA構建的新型影象生成模型,能夠接受多模態提示,透過創新的多模態特徵聯結器設計,有效整合文本和補充模態資訊。該模型透過凍結原始T2I擴散模型的所有引數,並僅調整一些額外層,揭示了預訓練的T2I擴散模型可以秘密接受多模態提示的有趣特性。
AutoStudio是一個基於大型語言模型的多輪互動式影象生成框架,它透過三個代理與一個基於穩定擴散的代理來生成高質量影象。該技術在多主題一致性方面取得了顯著進步,透過並行UNet結構和主題初始化生成方法,提高了影象生成的質量和一致性。
Stable Diffusion 3 Medium是Stability AI迄今為止釋出的最先進文本到影象生成模型。它具有2億引數,提供出色的細節、色彩和光照效果,支援多種風格。模型對長文本和複雜提示的理解能力強,能夠生成具有空間推理、構圖元素、動作和風格的影象。
LlamaGen是一個新的影象生成模型家族,它將大型語言模型的原始下一個token預測範式應用於視覺生成領網域。該模型透過適當的擴充,無需對視覺訊號的歸納偏差即可實作最先進的影象生成效能。LlamaGen重新審視了影象分詞器的設計空間、影象生成模型的可擴充性屬性以及它們的訓練資料質量。
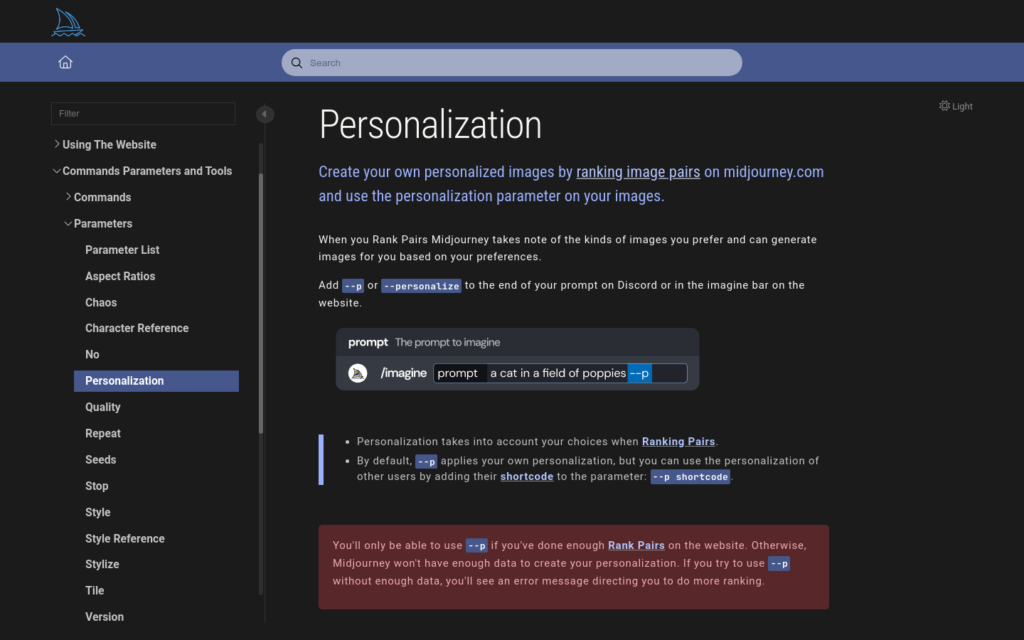
Midjourney是一個獨立的研究實驗室,專注於探索新的思想媒介和擴充人類想象力。它是一個自籌資金的小團隊,專注於設計、人類基礎設施和人工智慧。Midjourney Personalization透過使用者對影象對的評分來學習使用者的偏好,並根據這些偏好生成個性化的影象。
EasySdxlWebUi是一個開源專案,旨在簡化SdxlWebUi的安裝和使用過程,使得使用者可以更加方便地利用Stable Diffusion web UI和forge等工具進行影象生成。專案支援多種擴充功能,允許使用者透過web介面進行引數設定和影象生成,同時也支援自訂和自動化安裝,適合需要快速上手和高效生成影象的使用者。