Web LLM:將大型語言模型和聊天引入到 Web 瀏覽器中
Web LLM 是一個模組化、可定製的 JavaScript 包,可直接將語言模型聊天引入到 Web 瀏覽器中。一切都在瀏覽器內部執行,無需伺服器支援,並且透過 WebGPU 進行加速。它可以為大家構建 AI 助手提供很多有趣的機會,並在享受 GPU 加速時保護隱私。此專案是 MLC LLM 的附屬專案,MLC LLM 可以在 iPhone 和其他本地環境中本地執行 LLM。
Web LLM 是一個模組化、可定製的 JavaScript 包,可直接將語言模型聊天引入到 Web 瀏覽器中。一切都在瀏覽器內部執行,無需伺服器支援,並且透過 WebGPU 進行加速。它可以為大家構建 AI 助手提供很多有趣的機會,並在享受 GPU 加速時保護隱私。此專案是 MLC LLM 的附屬專案,MLC LLM 可以在 iPhone 和其他本地環境中本地執行 LLM。
Imp專案旨在提供一系列強大的多模態小語言模型(MSLMs)。我們的imp-v1-3b是一個擁有30億引數的強大MSLM,它建立在一個小而強大的SLM Phi-2(27億)和一個強大的視覺編碼器SigLIP(4億)之上,並在LLaVA-v1.5訓練集上進行了訓練。Imp-v1-3b在各種多模態基準測試中明顯優於類似模型規模的對手,甚至在各種多模態基準測試中表現略優於強大的LLaVA-7B模型。
Qwen-VL 是阿里雲推出的通用型視覺語言模型,具有強大的視覺理解和多模態推理能力。它支援零樣本影象描述、視覺問答、文字理解、影象地標定位等任務,在多個視覺基準測試中達到或超過當前最優水平。該模型採用 Transformer 結構,以 7B 引數規模進行預訓練,支援 448×448 解析度,可以端到端處理影象與文字的多模態輸入與輸出。Qwen-VL 的優勢包括通用性強、支援多語種、細粒度理解等。它可以廣泛應用於影象理解、視覺問答、影象標註、圖文生成等任務。
OLMo是一個開源的語言模型和訓練框架,由AI2研究院釋出。它提供了完整的訓練資料、程式碼、模型引數、評估程式碼等資源,使研究人員能夠訓練並實驗大規模語言模型。OLMo的優勢在於真正開放,使用者可以訪問從資料到模型的完整資訊,輔以豐富的檔案,便於研究人員進行開放式研究和協作。該框架降低了語言模型研究的門檻,使更多人參與進來推動語言模型技術進步。
Lepton是一個開源的自然語言處理平臺,提供語言理解、生成和推理能力。它採用Transformer模型架構,能夠進行多輪對話、問答、文字生成等任務。Lepton具有高效、可擴充套件的特點,可以在多個領域部署使用。
Patchscope是一個用於檢查大型語言模型(LLM)隱藏表示的統一框架。它能解釋模型行為,驗證其與人類價值觀的一致性。透過利用模型本身生成人類可理解的文字,我們提出利用模型本身來解釋其自然語言內部表示。我們展示了Patchscopes框架如何用於回答關於LLM計算的廣泛研究問題。我們發現,基於將表示投影到詞彙空間和干預LLM計算的先前可解釋性方法,可以被視為此框架的特殊例項。此外,Patchscope還開闢了新的可能性,例如使用更強大的模型來解釋較小模型的表示,並解鎖了自我糾正等新應用,如多跳推理。
Moonvalley 是一款突破性的文字到影片生成 AI 模型,可以從簡單的文字提示中建立出令人驚歎的高畫質影片和動畫。它採用先進的機器學習技術,能夠根據使用者輸入的文字提示,生成逼真、精美的影片和動畫。無論是製作電影、廣告、動畫短片還是個人創作,Moonvalley 都能幫助使用者快速將想法轉化為視覺作品。
Cappy是一種新型方法,旨在提高大型多工語言模型的效能和效率。它是一個輕量級的預訓練評分器,基於RoBERTa,僅有3.6億個引數。Cappy可獨立解決分類任務,或作為輔助元件提升語言模型效能。在下游任務中微調Cappy,可有效整合監督資訊,提高模型表現,且不需要反向傳播到語言模型引數,降低了記憶體需求。Cappy適用於開源和封閉原始碼的語言模型,是一種高效的模型微調方法。

KarpathyLLMChallenge是一個教育性質的網站,專注於解釋和展示語言模型(LLMs)中標記化的重要性和複雜性。它透過詳細的文章和例項,幫助使用者理解標記化如何影響語言模型的效能和能力。
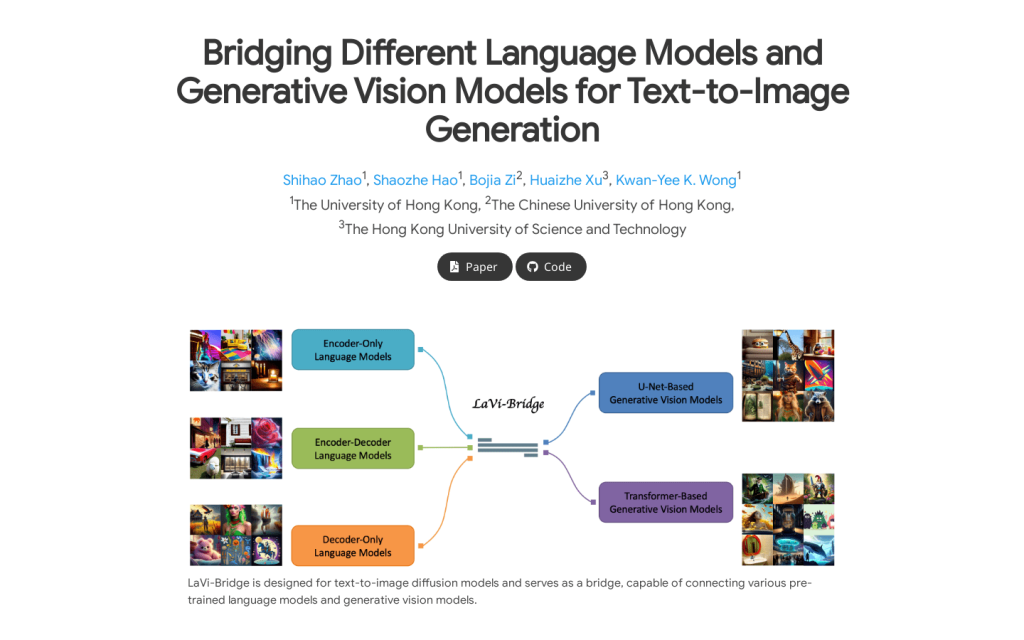
LaVi-Bridge是一種針對文字到影象擴散模型設計的橋接模型,能夠連線各種預訓練的語言模型和生成視覺模型。它透過利用LoRA和介面卡,提供了一種靈活的插拔式方法,無需修改原始語言和視覺模型的權重。該模型與各種語言模型和生成視覺模型相容,可容納不同的結構。在這一框架內,我們證明了透過整合更高階的模組(如更先進的語言模型或生成視覺模型)可以明顯提高文字對齊或影象質量等能力。該模型經過大量評估,證實了其有效性。