ArcaneLand:具備物品、任務和經驗系統的AI劇情大師
奇幻大陸是一款由多個ChatGPT智慧AI大腦驅動的文字冒險遊戲,具備完整的物品、任務和經驗系統。玩家可以透過與AI互動,升級角色、獲得物品、完成任務,並在遊戲中體驗豐富的劇情。定價:免費試玩。

奇幻大陸是一款由多個ChatGPT智慧AI大腦驅動的文字冒險遊戲,具備完整的物品、任務和經驗系統。玩家可以透過與AI互動,升級角色、獲得物品、完成任務,並在遊戲中體驗豐富的劇情。定價:免費試玩。
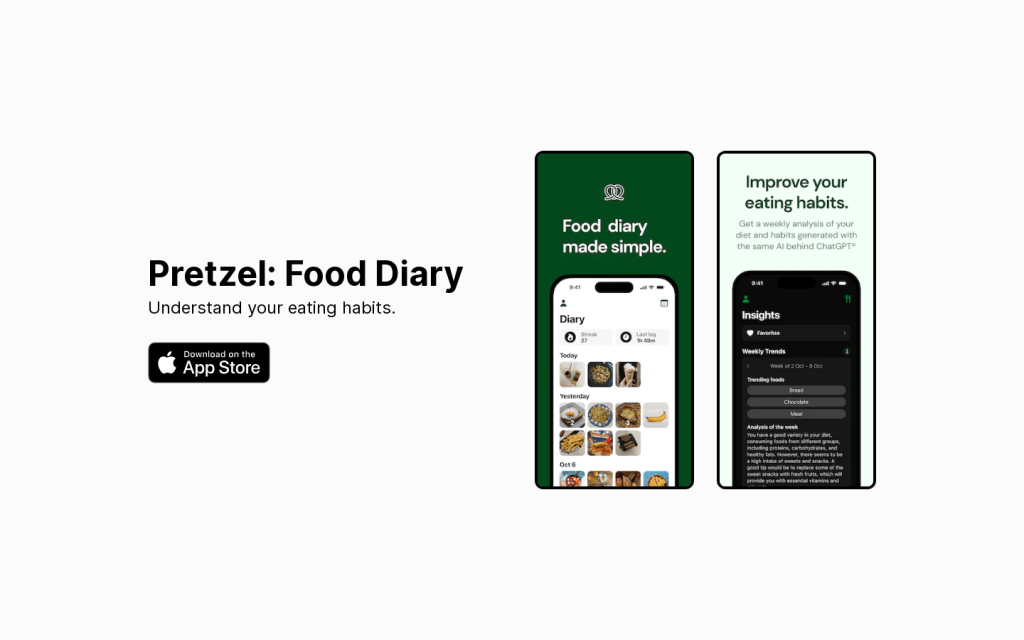
Pretzel食物日記APP透過記錄使用者的飲食習慣,分析飲食結構和營養構成,幫助使用者更好地瞭解自己的飲食習慣,達到管理體重、改善飲食的目的。該APP具有記錄飲食、生成報告、提醒使用者、統計熱量等功能。其優勢是介面簡潔,使用方便,資料統計詳細。定價合理,定位健康人群。

知乎直答是知乎推出的一款使用 AI 大模型等先進技術的產品,以知乎社群的優質內容為核心,多種資料來源為輔助,為人們提供一種全新的獲取可靠資訊的途徑。知乎直答是多智慧體系統,能夠滿足使用者多維度的需求;同時對生成結果進行溯源,以確保內容的可信、可控以及對智慧財產權和版權的尊重。

詩境主要功能就是根據使用者上傳的圖片分析主體和意境,匹配詩句,最終生成漂亮的卡片。不知道你們有沒有遇到過,就是拍了一幅很美的照片,想吟詩一首再發個朋友圈,奈何教育程度有限,往往想半天最後配了段大白話。這時候詩境就能派上用場,把圖片餵給她,讓她給你配個最符合當前畫面意境的詩。
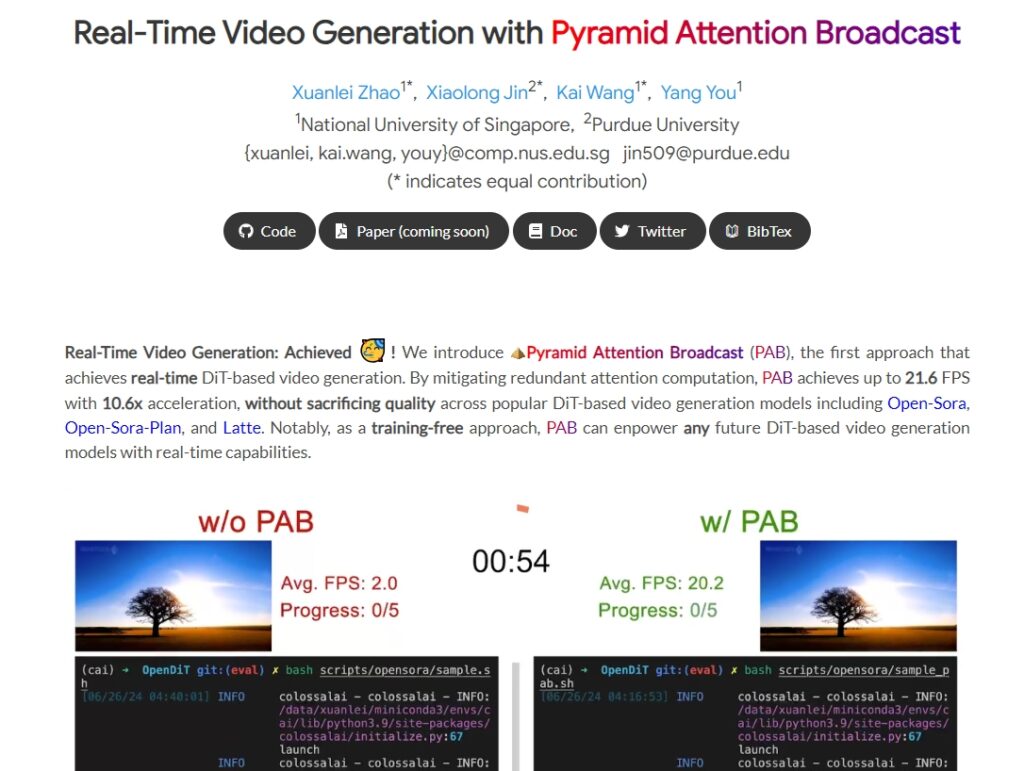
PAB 是一種用於實時影片生成的技術,透過 Pyramid Attention Broadcast 實作影片生成過程的加速,提供了高效的影片生成解決方案。該技術的主要優點包括實時性、高效性和質量保障。PAB 適用於需要實時影片生成能力的應用場景,為影片生成領網域帶來了重大突破。
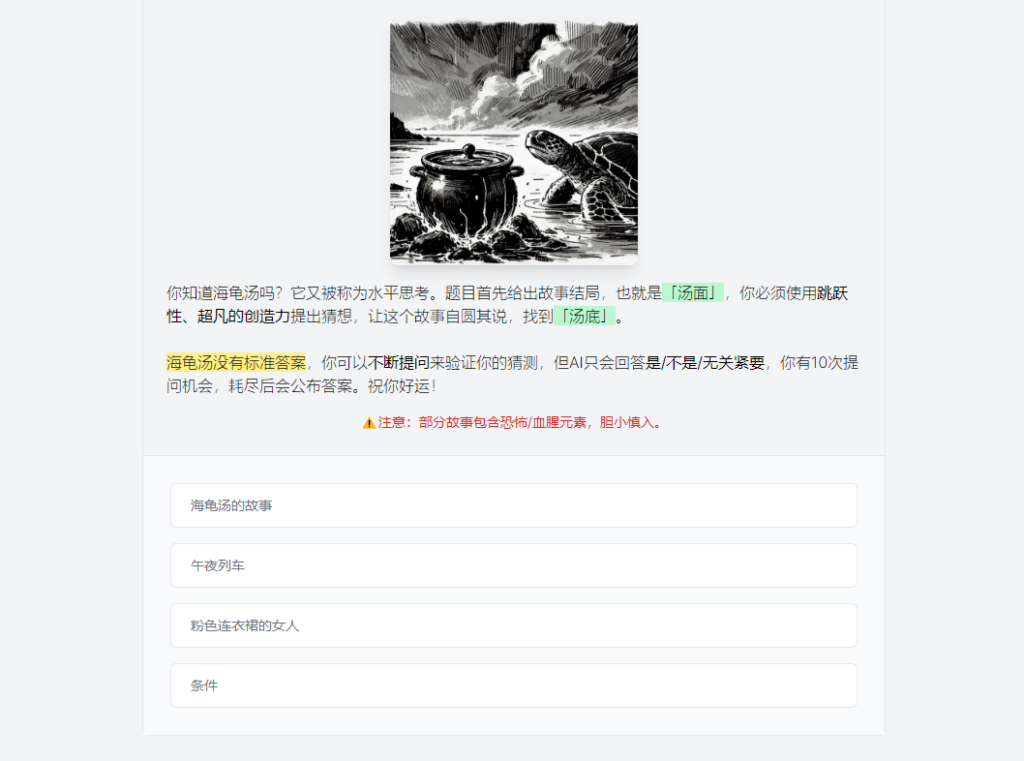
「湯很熱」 是一個以 AI 驅動的海龜湯遊戲平臺,旨在為使用者提供一個充滿懸疑和推理樂趣的遊戲體驗。使用者可以透過提出問題來推理故事的背後真相,挑戰自己的邏輯思維和想象力。部分故事包含恐怖和血腥元素,增加了遊戲的刺激感。
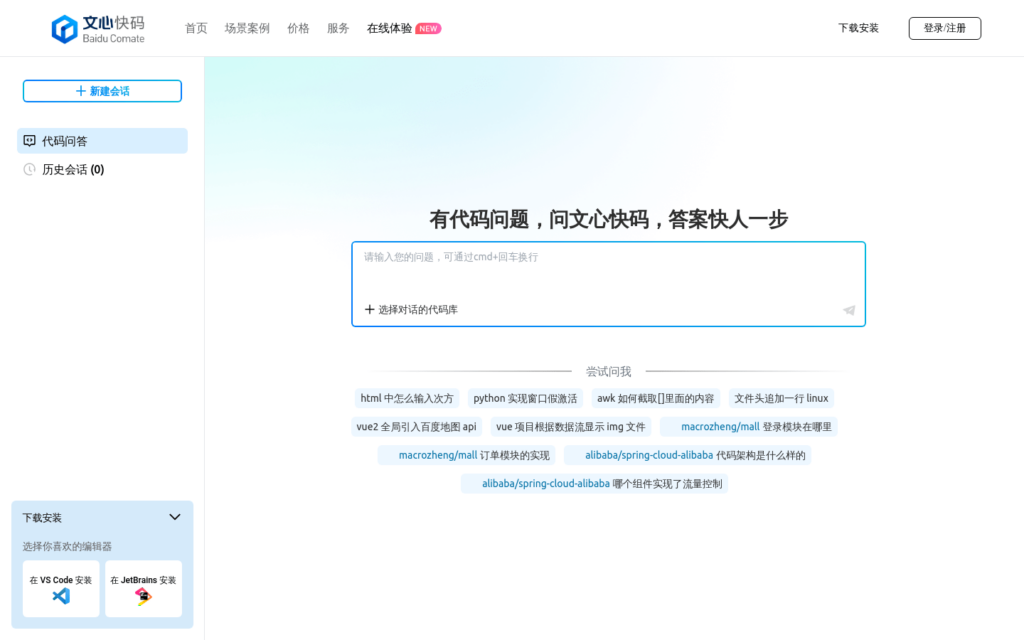
Comate 是基於文心大模型研發的程式設計輔助工具,支援上百種程式語言,提供自動程式碼生成、單元測試生成、註釋生成、研發智慧問答等能力。該工具的主要優點在於提高程式設計效率、減少重複性勞動,以及提供智慧的程式設計輔助功能。
CriticGPT 是基於 GPT-4 模型開發的工具,旨在幫助人類審查 ChatGPT 的程式碼輸出。透過辨識錯誤並提供留言,提高訓練師審查的準確性和效率。該工具能有效捕捉潛在問題,為 AI 模型的改進提供有力支援。
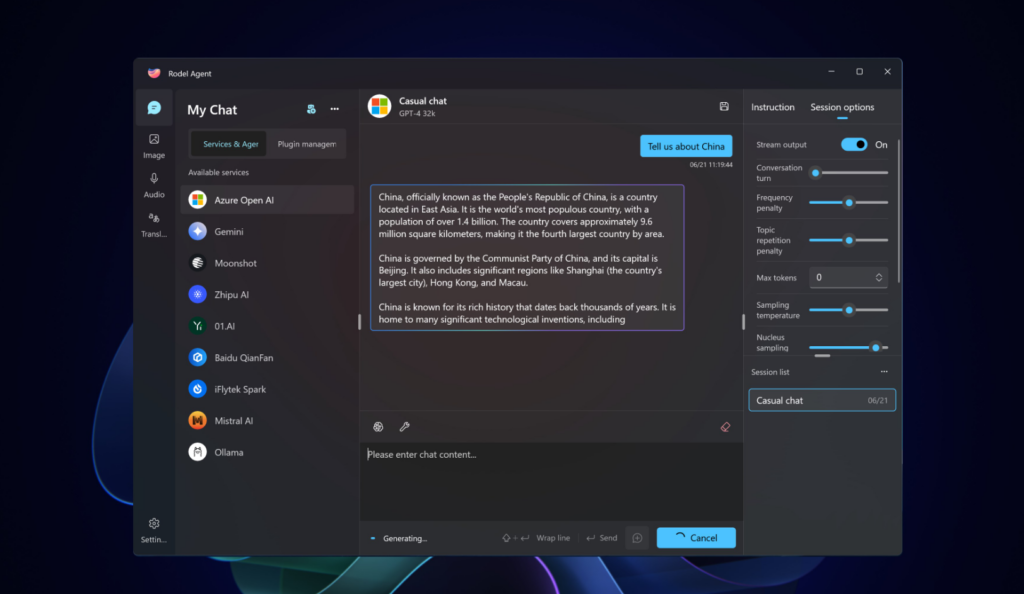
小幻助理是一款基於 AI 和 .NET 技術的智慧桌面應用,支援主流 AI 服務和開源模型,使用者可以呼叫各種服務進行組合,輕鬆構建屬於自己的助理工作流,讓使用者更加高效便捷地完成工作。

Ario 利用增強現實技術為一線工人提供易於使用的知識共享工具,以在最需要的時間、地點和方式提供資訊。Ario 結合了掃描辨識、資源庫和連線技術,可以提供以下功能: