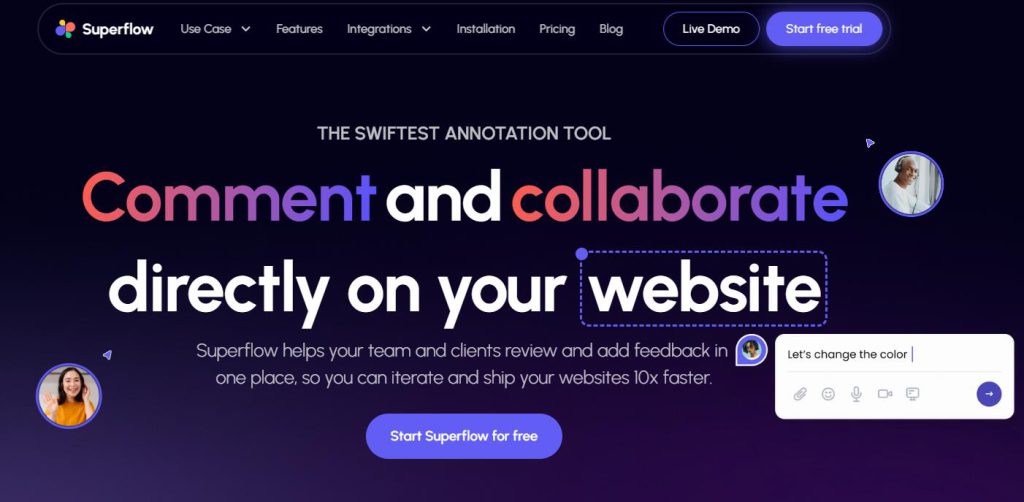
Magic Mate:智慧 AI 助手 – 在 WhatsApp 中與 ChatGPT 聊天、使用 Dalle 繪畫等
Magic Mate 是一款智慧 AI 助手,可以在 WhatsApp 中與 ChatGPT 聊天、使用 Dalle 繪畫,對影象進行上色和修復,使用自然語言編輯影象,翻譯音訊等。產品定價靈活,適用於個人和商業使用者。
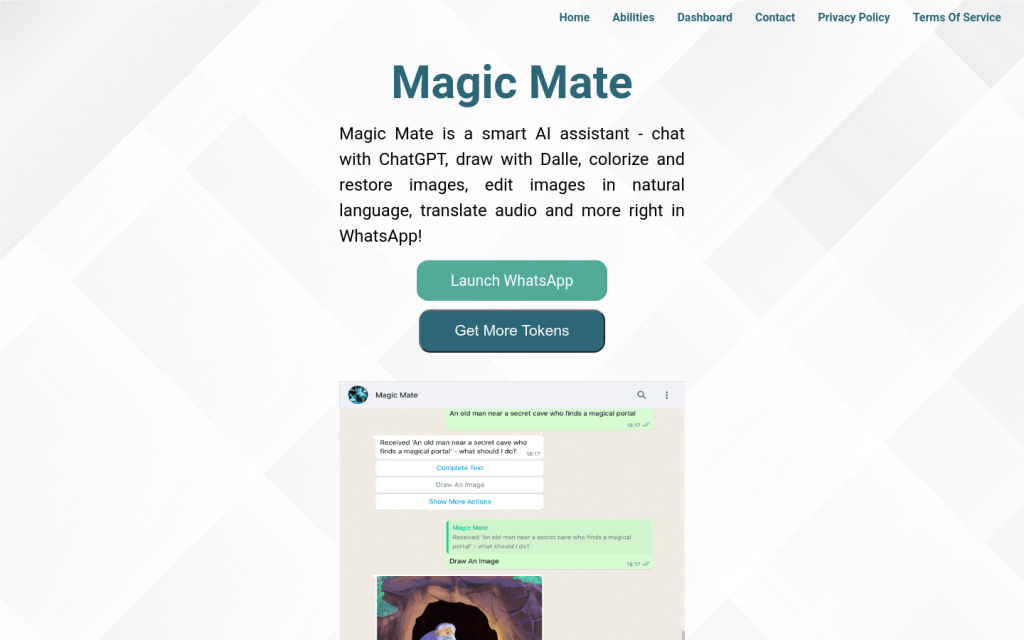
Magic Mate 是一款智慧 AI 助手,可以在 WhatsApp 中與 ChatGPT 聊天、使用 Dalle 繪畫,對影象進行上色和修復,使用自然語言編輯影象,翻譯音訊等。產品定價靈活,適用於個人和商業使用者。

Doodle Dash 是一個趣味的線上遊戲,它使用神經網路來預測玩家塗鴉的速度。玩家可以在遊戲中儘可能快地畫出指定的塗鴉,神經網路會根據你的畫速給出預測結果。這個遊戲基於? Transformers.js 開發。

Gaussian SLAM能夠從RGBD資料流重建可渲染的3D場景。它是第一個能夠以照片級真實感重建現實世界場景的神經RGBD SLAM方法。透過利用3D高斯作為場景表示的主要單元,我們克服了以往方法的侷限性。我們觀察到傳統的3D高斯在單目設定下很難使用:它們無法編碼準確的幾何資訊,並且很難透過單檢視順序監督進行最佳化。透過擴充套件傳統的3D高斯來編碼幾何資訊,並設計一種新穎的場景表示以及增長和最佳化它的方法,我們提出了一種能夠重建和渲染現實世界資料集的SLAM系統,而且不會犧牲速度和效率。高斯SLAM能夠重建和以照片級真實感渲染現實世界場景。我們在常見的合成和真實世界資料集上對我們的方法進行了評估,並將其與其他最先進的SLAM方法進行了比較。最後,我們證明了我們得到的最終3D場景表示可以透過高效的高斯飛濺渲染實時渲染。

Wild2Avatar是一個用於渲染被遮擋的野外單目影片中的人類外觀的神經渲染方法。它可以在真實場景下渲染人類,即使障礙物可能會阻擋相機視野並導致部分遮擋。該方法透過將場景分解為三部分(遮擋物、人類和背景)來實現,並使用特定的目標函式強制分離人類與遮擋物和背景,以確保人類模型的完整性。
Neuralhub是一個讓深度學習更簡單的平臺,它為AI愛好者、研究人員和工程師提供實驗和創新的環境。我們的目標不僅僅是提供工具,我們還在建立一個社區,一個可以分享和協作的地方。我們致力於透過彙集所有工具、研究和模型到一個協作空間,簡化當今的深度學習,使AI研究、學習和開發更容易獲取。

BakedAvatar是一種用於實時神經頭像合成的全新表示,可部署在標準多邊形光柵化流水線中。該方法從學習到的頭部等值面提取可變形的多層網格,並計算可烘焙到靜態紋理中的表情、姿勢和視角相關外觀,從而為實時4D頭像合成提供支援。我們提出了一個三階段的神經頭像合成流水線,包括學習連續變形、流形和輻射場,提取分層網格和紋理,以及透過微分光柵化來微調紋理細節。實驗結果表明,我們的表示產生了與其他最先進方法相當的綜合結果,並顯著減少了所需的推理時間。我們進一步展示了從單眼影片中產生的各種頭像合成結果,包括檢視合成、面部重現、表情編輯和姿勢編輯,所有這些都以互動式幀率進行。
通用預測學習器是一種利用元學習的強大方法,能夠快速從有限資料中學習新任務。透過廣泛接觸不同的任務,可以獲得通用的表示,從而實現通用問題解決。本產品探索了將最強大的通用預測器——Solomonoff歸納(SI)——透過元學習的方式進行攤銷的潛力。我們利用通用圖靈機(UTM)生成訓練資料,讓網路接觸到廣泛的模式。我們提供了UTM資料生成過程和元訓練協議的理論分析。我們使用不同複雜度和普適性的演演算法資料生成器對神經架構(如LSTM、Transformer)進行了全面的實驗。我們的結果表明,UTM資料是元學習的寶貴資源,可以用來訓練能夠學習通用預測策略的神經網路。

Visnet是一個全面的、無頭的、多相容的神經網路介面框架,主要用於自然語言處理和深度視覺系統。它具有模組化的前端、無伺服器架構和多相容性,並提供了REST API和Websocket介面。它包含了多個核心AI模型,如翻譯、車牌識別和人臉特徵匹配等。Visnet可廣泛應用於監控、無人機檢測、影象和影片分析等領域。

Midjourney for Slack是Midjourney的非官方社區建立的Slack外掛。直接在您的公司Slack工作區中使用Midjourney機器人,與團隊一起發揮創意。支援實時協作、影象生成、反饋和批准等功能。首次使用前5次影象生成免費,之後需要升級到付費計劃。