Manot:洞察管理平臺
Manot洞察管理平臺透過準確定位改進計算機視覺模型的表現。它為產品經理和工程師提供了可操作的見解,以便他們能夠確定計算機視覺模型失敗的原因。
LensAI是一個基於人工智慧的上下文廣告平臺,透過影片和影象分析將廣告直接放置在對象中,實現有效的流量變現。LensAI識別對象、標誌、動作和上下文,並將其與相關廣告進行匹配,精細調整定向,提供顯著的廣告效果和高回報率。LensAI提供了先進的圖片和影片廣告解決方案,為數字廣告生態系統的所有關鍵利益相關者帶來了利益。

美圖AI開放平臺專注於人臉技術、人體技術、影象識別、影象處理、影象生成等核心領域,為客戶提供經市場驗證的專業AI演演算法服務和解決方案。平臺提供人臉技術、人體技術、影象識別、影象處理、影象生成等多種影象AI服務,支援Web API、Mobile SDK等多種接入方式,可應用於企業服務、美妝門店、醫療美容、智慧硬體等多個行業場景,幫助企業快速進行影象AI能力打通和應用。
SIFU是一個利用側檢視像重建高質量3D服裝虛擬人物模型的方法。它的核心創新點是提出了一種新的基於側檢視像的隱式函式,可以增強特徵提取和提高几何精度。此外,SIFU還引入了一種3D一致的紋理最佳化過程,可大大提升紋理質量,藉助文字到影象的diffusion模型實現紋理編輯。SIFU擅長處理複雜姿勢和寬鬆衣物,是實際應用中理想的解決方案。
Human101是一個快速從單檢視重建人體的框架。它能夠在100秒內訓練3D高斯模型,並以60FPS以上渲染1024解析度的影象,而無需預先儲存每幀的高斯屬性。Human101管道如下:首先,從單檢視影片中提取2D人體姿態。然後,利用姿態驅動3D模擬器生成匹配的3D骨架動畫。最後,基於動畫構建時間相關的3D高斯模型,進行實時渲染。
Adversarial Diffusion Distillation是一個實時影象編輯平臺,可以透過手機、平板電腦或計算機將任何物理媒介轉換為數字媒介,並在任何地方進行編輯。它使用先進的計算機視覺技術,可以快速、輕鬆地將物理媒介轉換為數字媒介,包括紙張、牆壁、白板、書籍等。Adversarial Diffusion Distillation可以幫助使用者提高工作效率,減少時間和成本。
VCoder是一個介面卡,可透過輔助感知模式作為控制輸入來提高多模態大型語言模型在對象級視覺任務上的效能。VCoder LLaVA是基於LLaVA-1.5構建的。VCoder不微調LLaVA-1.5的引數,因此在通用的問答基準測試中的效能與LLaVA-1.5相同。VCoder在COST資料集上進行了基準測試,在語義、例項和全景分割任務上都取得了不錯的效能。作者還發布了模型的檢測結果和預訓練模型。

Wild2Avatar是一個用於渲染被遮擋的野外單目影片中的人類外觀的神經渲染方法。它可以在真實場景下渲染人類,即使障礙物可能會阻擋相機視野並導致部分遮擋。該方法透過將場景分解為三部分(遮擋物、人類和背景)來實現,並使用特定的目標函式強制分離人類與遮擋物和背景,以確保人類模型的完整性。
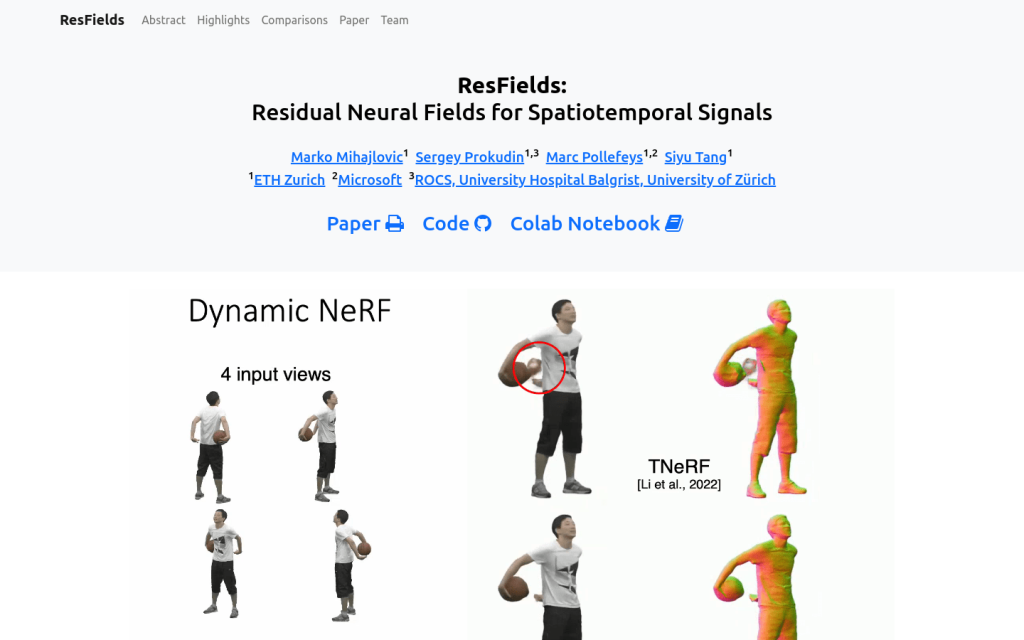
ResFields是一類專門設計用於有效表示覆雜時空訊號的網路。它將時變權重引入多層感知機中,利用可訓練的殘差引數增強了模型的表達能力。該方法可以無縫整合到現有技術中,並可顯著提高各種具有挑戰性的任務的結果,如2D影片逼近、動態形狀建模和動態NeRF重建等。
LayerNext是一款綜合的AI資料管理平臺,幫助計算機視覺團隊在大規模的資料集上進行資料收集、整理、標註和搜尋。透過LayerNext,使用者可以輕鬆地視覺化資料、快速發現資料集中的模式或問題,以及快速搜尋特定對象。平臺還提供SDK和API,可以與任何計算機視覺應用、服務或基礎設施無縫整合。LayerNext的目標是簡化計算機視覺工作流程,使團隊可以專注於業務相關的事務。